Let’s say you have been tasked to design a system capable of detecting vehicles on a road such as the one below,
Surely, this seems like a job for a Deep Neural Network, right?
This means you have to get a lot of data, label them, then train a model, tune its performance and serve it on a system capable of running it in real-time.
This sounds like a lot of work and it begs the question: Is deep learning the only way to do so?
What if I tell you that you can solve this problem and many others like this using a much simpler approach, and with this approach, you will not have to spend days collecting data or training deep learning models. And the approach is also lightweight so it will run on almost any machine!
Alright, what exactly are we talking about here?
This simpler approach relies on a popular Computer Vision technique called Contour Detection. A handy technique that can save the day when dealing with vision problems such as the one above. Although not as generalizable as Deep Neural Networks, contour detection can prove robust under controlled circumstances, requiring minimum time investment and effort to build vision applications.
Just to give you a glimpse of what you can build with contour detection, have a look at some of the applications that I made using contour detection.
and there are many other applications that you can build too, once you learn about what contour Detection is and how you can use it, in fact, I have an entire course that will help you master contours for building computer vision applications.
Since Contours is a lengthy topic, I’ll be breaking down Contours into a 4 parts series. This is the first part where we discuss the basics of contour detection in OpenCV, how to use it, and go over various preprocessing techniques required for Contour Detection.
A contour can be simply defined as a curve that joins a set of points enclosing an area having the same color or intensity. This area of uniform color or intensity forms the object that we are trying to detect, and the curve enclosing this area is the contour representing the shape of the object. So essentially, contour detection works similarly to edge-detection but with the restriction that the edges detected must form a closed path.
Still confused? Just have a look at the GIF below. You can see four shapes, which on a pixel level forms when certain pixels share the same color which is distinct from the background color. Contour detection identifies each of the border pixels that is distinct from the background forming an enclosed, continuous path of pixels that form the line representing the contour.
Now, let’s see how this works in OpenCV.
Import the Libraries
Let’s start by importing the required libraries.
import cv2
import numpy as np
import matplotlib.pyplot as plt
Read an Image
Next, we will read an image below containing a bunch of shapes for which we will find the contours.
# Read the image
Gray_image = cv2.imread('media/image.png', 0)
# Display the image
plt.figure(figsize=[10,10])
plt.imshow(image1, cmap='gray');plt.title("Original Image");plt.axis("off");
OpenCV saves us the trouble of writing lengthy algorithms for contour detection and provides a handy function findContours() that analyzes the topological structure of the binary image by border following, a contour detection technique developed in 1985.
The findContours() function takes a binary image as input. The foreground is assumed to be white, and the background is assumed to be black. If that is not the case, then you can invert the image pixels using the cv2.bitwise_not() function.
image – It is the input image (8-bit single-channel). Non-zero pixels are treated as 1’s. Zero pixels remain 0’s, so the image is treated as binary. You can use compare, inRange, threshold, adaptiveThreshold, Canny, and others to create a binary image out of a grayscale or color one.
mode – It is the contour retrieval mode, ( RETR_EXTERNAL, RETR_LIST, RETR_CCOMP, RETR_TREE )
method – It is the contour approximation method. ( CHAIN_APPROX_NONE, CHAIN_APPROX_SIMPLE, CHAIN_APPROX_TC89_L1, etc )
offset – It is the optional offset by which every contour point is shifted. This is useful if the contours are extracted from the image ROI, and then they should be analyzed in the whole image context.
Returns:
contours – It is the detected contours. Each contour is stored as a vector of points.
hierarchy – It is the optional output vector containing information about the image topology. It has been described in detail in the video above.
We will go through all the important parameters in a while. For now, let’s detect some contours in the image that we read above.
Since the image read above only contains a single channel instead of three, and even that channel is in the binary state (black & white) so it can be directly passed to the findContours() function without requiring any preprocessing.
# Find all contours in the image.
contours, hierarchy = cv2.findContours(Gray_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Display the total number of contours found.
print("Number of contours found = {}".format(len(contours)))
Number of contours found = 5
Visualizing the Contours detected
As you can see the cv2.findContours() function was able to correctly detect the 5 external shapes in the image. But how do we know that the detections were correct? Thankfully we can easily visualize the detected contours using the cv2.drawContours() function which simply draws the detected contours onto an image.
image – It is the image on which contours are to be drawn.
contours – It is point vector(s) representing the contour(s). It is usually an array of contours.
contourIdx – It is the parameter, indicating a contour to draw. If it is negative, all the contours are drawn.
color – It is the color of the contours.
thickness – It is the thickness of lines the contours are drawn with. If it is negative (for example, thickness=FILLED ), the contour interiors are drawn.
lineType – It is the type of line. You can find the possible options here.
hierarchy – It is the optional information about hierarchy. It is only needed if you want to draw only some of the contours (see maxLevel ).
maxLevel – It is the maximal level for drawn contours. If it is 0, only the specified contour is drawn. If it is 1, the function draws the contour(s) and all the nested contours. If it is 2, the function draws the contours, all the nested contours, all the nested-to-nested contours, and so on. This parameter is only taken into account when there is a hierarchy available.
offset – It is the optional contour shift parameter. Shift all the drawn contours by the specified offset=(dx, dy).
Let’s see how it works.
# Read the image in color mode for drawing purposes.
image1 = cv2.imread('media/image.png')
# Make a copy of the source image.
image1_copy = image1.copy()
# Draw all the contours.
cv2.drawContours(image1_copy, contours, -1, (0,255,0), 3)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");
This seems to have worked nicely. But again, this is a pre-processed image that is easy to work with, which will not be the case when working with a real-world problem where you will have to pre-process the image before detecting contours. So let’s have a look at some common pre-processing techniques below.
Pre-processing images For Contour Detection
As you have seen above that the cv2.findContours() functions takes in as input a single channel binary image, however, in most cases the original image will not be a binary image. Detecting contours in colored images require pre-processing to produce a single-channel binary image that can be then used for contour detection. Ideally, this processed image should have the target objects in the foreground.
The two most commonly used techniques for this pre-processing are:
Thresholding based Pre-processing
Edge Based Pre-processing
Below we will see how you can accurately detect contours using these techniques.
Thresholding based Pre-processing For Contours
So to detect contours in colored images we can perform fixed level image thresholding to produce a binary image, that can be then used for contour detection. Let’s see how this works.
First, read a sample image using the function cv2.imread() and display the image using the matplotlib library.
# Read the image
image2 = cv2.imread('media/tree.jpg')
# Display the image
plt.figure(figsize=[10,10])
plt.imshow(image2[:,:,::-1]);plt.title("Original Image");plt.axis("off");
We will try to find the contour for the tree above, first without using any thresholding to see how the result will look like.
The first step is to convert the 3-channel BGR image to a single-channel image using the cv2.cvtColor() function.
# Make a copy of the source image.
image2_copy = image2.copy()
# Convert the image to gray-scale
gray = cv2.cvtColor(image2_copy, cv2.COLOR_BGR2GRAY)
# Display the result
plt.imshow(gray, cmap="gray");plt.title("Gray-scale Image");plt.axis("off");
Contour detection on the image above will only result in a contour outlining the edges of the image. This is because the cv2.findContours() function expects the foreground to be white, and the background to be black, which is not the case above so we need to invert the colors using cv2.bitwise_not().
# Invert the colours
gray_inverted = cv2.bitwise_not(gray)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(gray_inverted ,cmap="gray");plt.title("Bitwise Inverted");plt.axis("off");
The inverted image with a black background and white foreground can now be used for contour detection.
# Find the contours from the inverted gray-scale image
contours, hierarchy = cv2.findContours(gray_inverted, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# draw all contours
cv2.drawContours(image2_copy, contours, -1, (0, 255, 0), 2)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image2_copy[:,:,::-1]);plt.title("Contours Detected");plt.axis("off");
The result is far from ideal. As you can see the contours detected poorly align with the boundary of the tree in the image. This is because we only fulfilled the requirement of a single-channel image, but we did not make sure that the image was binary in colors, leaving noise along the edges. This is why we need thresholding to provide us a binary image.
Thresholding the image
We will use the function cv2.threshold() to perform thresholding. The function takes in as input the gray-scale image, applies fixed level thresholding, and returns a binary image. In this case, all the pixel values below 100 are set to 0(black) while the ones above are set to 255(white). Since the image has already been inverted, cv2.THRESH_BINARY is used, but if the image is not inverted, cv2.THRESH_BINARY_INV should be used. Also, the fixed level used must be able to correctly segment the target object as foreground(white).
# Create a binary thresholded image
_, binary = cv2.threshold(gray_inverted, 100, 255, cv2.THRESH_BINARY)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(binary, cmap="gray");plt.title("Binary Image");plt.axis("off");
The resultant image above is ideally what the cv2.findContours() function is expecting. A single-channelbinary image with Black background and white foreground.
# Make a copy of the source image.
image2_copy2 = image2.copy()
# find the contours from the thresholded image
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# draw all the contours found
image2_copy2 = cv2.drawContours(image2_copy2, contours, -1, (0, 0, 255), 2)
# Plot both of the resuts for comparison
plt.figure(figsize=[15,15])
plt.subplot(121);plt.imshow(image2_copy[:,:,::-1]);plt.title("Without Thresholding");plt.axis('off')
plt.subplot(122);plt.imshow(image2_copy2[:,:,::-1]);plt.title("With Threshloding");plt.axis('off');
The difference is clear. Binarizing the image helps get rid of all the noise at the edges of objects, resulting in accurate contour detection.
Edge Based Pre-processing For Contours
Thresholding works well for simple images with fewer variations in colors, however, for complex images, it’s not always easy to do background-foreground segmentation using thresholding. In these cases creating the binary image using edge detection yields better results.
Let’s read another sample image.
# Read the image
image3 = cv2.imread('media/chess.jpg')
# Display the image
plt.figure(figsize=[10,10])
plt.imshow(image3[:,:,::-1]);plt.title("Original Image");plt.axis("off");
It’s obvious that simple fixed level thresholding wouldn’t work for this image. You will always end up with only half the chess pieces in the foreground only. So instead we will use the function cv2.Canny() for detecting the edges in the image. cv2.Canny() returns a single channel binary image which is all we need to perform contour detection in the next step. We also make use of the cv2.GaussianBlur() function to smoothen any noise in the image.
# Blur the image to remove noise
blurred_image = cv2.GaussianBlur(image3.copy(),(5,5),0)
# Apply canny edge detection
edges = cv2.Canny(blurred_image, 100, 160)
# Display the resultant binary image of edges
plt.figure(figsize=[10,10])
plt.imshow(edges,cmap='Greys_r');plt.title("Edges Image");plt.axis("off");
Now, using the edges detected, we can perform contour detection.
# Detect the contour using the edges
contours, hierarchy = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Draw the contours
image3_copy = image3.copy()
cv2.drawContours(image3_copy, contours, -1, (0, 255, 0), 2)
# Display the drawn contours
plt.figure(figsize=[10,10])
plt.imshow(image3_copy[:,:,::-1]);plt.title("Contours Detected");plt.axis("off");
In comparison, if we were to use thresholding as before it would yield a poor result that will only manage to correctly outline half of the chess pieces in the image at a time. So for a fair comparison, we will use cv2.adaptiveThreshold() to perform adaptive thresholding which adjusts to different color intensities in the image.
image3_copy2 = image3.copy()
# Remove noise from the image
blurred = cv2.GaussianBlur(image3_copy2,(3,3),0)
# Convert the image to gray-scale
gray = cv2.cvtColor(blurred, cv2.COLOR_BGR2GRAY)
# Perform adaptive thresholding
binary = cv2.adaptiveThreshold(gray,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY_INV, 11, 5)
# Detect and Draw contours
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(image3_copy2, contours, -1, (0, 255, 0), 2)
# Plotting both results for comparison
plt.figure(figsize=[14,10])
plt.subplot(211);plt.imshow(image3_copy2[:,:,::-1]);plt.title("Using Adaptive Thresholding");plt.axis('off')
plt.subplot(212);plt.imshow(image3_copy[:,:,::-1]);plt.title("Using Edge Detection");plt.axis('off');
As can be seen above, using canny edge detection results in finer contour detection.
Drawing a selected Contour
So far we have only drawn all of the detected contours in an image, but what if we want to only draw certain contours?
The contours returned by the cv2.findContours() is a python list where the ith element is the contour for a certain shape in the image. Therefore if we are interested in just drawing one of the contours we can simply index it from the contours list and draw the selected contour only.
image1_copy = image1.copy()
# Find all contours in the image.
contours, hierarchy = cv2.findContours(Gray_image, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
# Select a contour
index = 5
contour_selected = contours[index]
# Draw the selected contour
cv2.drawContours(image1_copy, contour_selected, -1, (0,255,0), 6);
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");plt.title('Selected Contour: ' + str(index));
Now let’s modify our code using a for loop to draw all of the contours separately.
image1_copy = image1.copy()
# Create a figure object for displaying the images
plt.figure(figsize=[15,30])
# Convert to grayscale.
imageGray = cv2.cvtColor(image1_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image
contours, hierarchy = cv2.findContours(imageGray, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
# Loop over the contours
for i,cont in enumerate(contours):
# Draw the ith contour
image1_copy = cv2.drawContours(image1.copy(), cont, -1, (0,255,0), 6)
# Add a subplot to the figure
plt.subplot(4, 2, i+1)
# Turn off the axis
plt.axis("off");plt.title('contour ' +str(i))
# Display the image in the subplot
plt.imshow(image1_copy)
Retrieval Modes
Function cv2.findContours() does not only returns the contours found in an image but also returns valuable information about the hierarchy of the contours in the image. This hierarchy encodes how the contours may be arranged in the image, e.g, they may be nested within another contour. Often we are more interested in some contours than others. For example, you may only want to retrieve the external contour of an object.
Using the Retrieval Modes specified, the cv2.findContours() function can determine how the contours are to be returned or arranged in a hierarchy.
For more information on Retrieval modes and contour hierarchy Read here.
Some of the important retrieval modes are:
cv2.RETR_EXTERNAL – retrieves only the extreme outer contours.
cv2.RETR_LIST – retrieves all of the contours without establishing any hierarchical relationships.
cv2.RETR_TREE – retrieves all of the contours and reconstructs a full hierarchy of nested contours.
cv2.RETR_CCOMP – retrieves all of the contours and organizes them into a two-level hierarchy. At the top level, there are external boundaries of the components. At the second level, there are boundaries of the holes. If there is another contour inside a hole of a connected component, it is still put at the top level.
Below we will have a look at how each of these modes return the contours.
cv2.RETR_LIST
cv2.RETR_LIST simply retrieves all of the contours without establishing any hierarchical relationships between them. All of the contours can be said to have no parent or child relationship with another contour.
image1_copy = image1.copy()
# Convert to gray-scale
imageGray = cv2.cvtColor(image1_copy, cv2.COLOR_BGR2GRAY)
# Find and return all contours in the image using the RETR_LIST mode
contours, hierarchy = cv2.findContours(imageGray, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# Draw all contours.
cv2.drawContours(image1_copy, contours, -1, (0,255,0), 3);
# Print the number of Contours returned
print("Number of Contours Returned: {}".format(len(contours)))
# Display the results.
plt.figure(figsize=[10,10])
plt.imshow(image1_copy);plt.axis("off");plt.title('Retrieval Mode: RETR_LIST');
Number of Contours Returned: 8
cv2.RETR_EXTERNAL
cv2.RETR_EXTERNAL retrieves only the extreme outer contours i.e the contours not having any parent contour.
image1_copy = image1.copy()
# Find all contours in the image.
contours, hierarchy = cv2.findContours(imageGray, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Draw all the contours.
cv2.drawContours(image1_copy, contours, -1, (0,255,0), 3);
# Print the number of Contours returned
print("Number of Contours Returned: {}".format(len(contours)))
# Display the results.
plt.figure(figsize=[10,10])
plt.imshow(image1_copy);plt.axis("off");plt.title('Retrieval Mode: RETR_EXTERNAL');
Number of Contours Returned: 5
cv2.RETR_TREE
cv2.RETR_TREE retrieves all of the contours and constructs a full hierarchy of nested contours.
src_copy = image1.copy()
# Convert to gray-scale
imageGray = cv2.cvtColor(src_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image while maintaining a hierarchy
contours, hierarchy = cv2.findContours(imageGray, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Draw all the contours.
contour_image = cv2.drawContours(src_copy, contours, -1, (0,255,0), 3);
# Print the number of Contours returned
print("Number of Contours Returned: {}".format(len(contours)))
# Display the results.
plt.figure(figsize=[10,10])
plt.imshow(contour_image);plt.axis("off");plt.title('Retrieval Mode: RETR_TREE');
Number of Contours Returned: 8
cv2.RETR_CCOMP
cv2.RETR_CCOMP retrieves all of the contours and organizes them into a two-level hierarchy. At the top level, there are external boundaries of the object. At the second level, there are boundaries of the holes in object. If there is another contour inside that hole, it is still put at the top level.
To visualize the two levels we check for the contours that do not have any parent i.e the fourth value in their hierarchy [Next, Previous, First_Child, Parent] is set to -1. These contours form the first level and are represented with green color while all other are second-level contours represented in red.
src_copy = image1.copy()
imageGray = cv2.cvtColor(src_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image using RETE_CCOMP method
contours, hierarchy = cv2.findContours(imageGray, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
# Loop over all the contours detected
for i,cont in enumerate(contours):
# If the contour is at first level draw it in green
if hierarchy[0][i][3] == -1:
src_copy = cv2.drawContours(src_copy, cont, -1, (0,255,0), 3)
# else draw the contour in Red
else:
src_copy = cv2.drawContours(src_copy, cont, -1, (255,0,0), 3)
# Print the number of Contours returned
print("Number of Contours Returned: {}".format(len(contours)))
# Display the results.
plt.figure(figsize=[10,10])
plt.imshow(src_copy);plt.axis("off");plt.title('Retrieval Mode: RETR_CCOMP');
Number of Contours Returned: 8
[optin-monster slug=”d8wgq6fdm5mppdb5fi99″]
Summary
Alright, In the first part of the series we have unpacked a lot of important things about contour detection and how it works. We discussed what types of applications you can build using Contour Detection and the circumstances under which it works most effectively.
We saw how you can effectively detect contours and visualize them too using OpenCV.
The post also went over some of the most common pre-processing techniques used prior to contour detection.
Thresholding based Pre-processing
Edge Based Pre-processing
which will help you get accurate results with contour detection. But these are not the only contour detection techniques, ultimately, it depends on what type of problem you are trying to solve, and figuring out the appropriate pre-processing to use is the key to contour detection. Start by asking what properties distinguish the target object from the rest of the image? Then figure out the best way you can use to isolate those properties.
We also went over the important Retrieval Modes that can be used to change how the hierarchy of the detected contours works or even change what type of contours are detected. Additionally, you can always use the hierarchy to only extract the contours you want, e.g. retrieve only the contours at level three.
This was the first part of the series but there are four more to come in which we will dive deeper into contour detection with OpenCV and also build a cool vision application using contour Detection!
You can reach out to me personally for a 1 on 1 consultation session in AI/computer vision regarding your project. Our talented team of vision engineers will help you every step of the way. Get on a call with me directlyhere.
Ready to seriously dive into State of the Art AI & Computer Vision? Then Sign up for these premium Courses by Bleed AI
In the previous post of this series, we introduced you to contour detection, a popular computer vision technique that you must have in your bag of tricks when dealing with computer vision problems. We discussed how we can detect contours for an object in an image, the pre-processing steps involved to prepare the image for contour detection, and we also went over many of the useful retrieval modes that you can use when detecting contours.
But detecting and drawing contours alone won’t cut it if you want to build powerful computer vision applications. Once detected, the contours need to be processed to make them useful for building cool applications such as the one below.
This is why in this second part of the series we will learn how we can perform different contour manipulations to extract useful information from the detected contours. Using this information you can build application such as the one above and many others, once you learn about how to effectively use and manipulate contours, in fact, I have an entire course that will help you master contours for building computer vision applications.
This post will be the second part of our new Contour Detection 101 series. All 4 posts in the series are titled as:
So if you haven’t seen the previous post and you are new to contour detection make sure you do check it out.
In part two of the series, the contour manipulation techniques we are going to learn will enable us to perform some important tasks such as extracting the largest contour in an image, sorting contours in terms of size, extracting bounding box regions of a targeted contour, etc. These techniques also form the building blocks for building robust classical vision applications.
So without further Ado, let’s get started.
[optin-monster slug=”sidmzfsvlmvh8o3kc5c1″]
Import the Libraries
Let’s start by importing the required libraries.
import cv2
import numpy as np
import matplotlib.pyplot as plt
Read an Image
# Read the image
image1 = cv2.imread('media/image.png')
# Display the image
plt.figure(figsize=[10,10])
plt.imshow(image1[:,:,::-1]);plt.title("Original Image");plt.axis("off");
Detect and draw Contours
Next, we will detect and draw contours on the image as before using the cv2.findContours()andcv2.drawContours()functions.
# Make a copy of the original image so it is not overwritten
image1_copy = image1.copy()
# Convert to grayscale.
image_gray = cv2.cvtColor(image1_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image.
contours, hierarchy = cv2.findContours(image_gray, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
# Draw the selected contour
cv2.drawContours(image1_copy, contours, -1, (0,255,0), 3);
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");plt.title('Contours Drawn');
Extracting the Largest Contour in the image
When building vision applications using contours, often we are interested in retrieving the contour of the largest object in the image and discard others as noise. This can be done using the built-in python’s max() function with the contours list. The max() function takes in as input the contours list along with a key parameter which refers to the single argument function used to customize the sort order. The function is applied to each item on the iterable. So for retrieving the largest contour we use the key cv2.contourArea which is a function that returns the area of a contour. It is applied to each contour in the list and then the max() function returns the largest contour based on its area.
image1_copy = image1.copy()
# Convert to grayscale
gray_image = cv2.cvtColor(image1_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image.
contours, hierarchy = cv2.findContours(gray_image, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
# Retreive the biggest contour
biggest_contour = max(contours, key = cv2.contourArea)
# Draw the biggest contour
cv2.drawContours(image1_copy, biggest_contour, -1, (0,255,0), 4);
# Display the results
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");
Sorting Contours in terms of size
Extracting the largest contour worked out well, but sometimes we are interested in more than one contour from a sorted list of contours. In such cases, another built-in python function sorted() can be used instead. sorted() function also takes in the optional key parameter which we use as before for returning the area of each contour. Then the contours are sorted based on area and the resultant list is returned. We also specify the order of sort reverse = True i.e in descending order of area size.
image1_copy = image1.copy()
# Convert to grayscale.
imageGray = cv2.cvtColor(image1_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image.
contours, hierarchy = cv2.findContours(imageGray, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
# Sort the contours in decreasing order
sorted_contours = sorted(contours, key=cv2.contourArea, reverse= True)
# Draw largest 3 contours
for i, cont in enumerate(sorted_contours[:3],1):
# Draw the contour
cv2.drawContours(image1_copy, cont, -1, (0,255,0), 3)
# Display the position of contour in sorted list
cv2.putText(image1_copy, str(i), (cont[0,0,0], cont[0,0,1]-10), cv2.FONT_HERSHEY_SIMPLEX, 1.4, (0, 255, 0),4)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");
Drawing a rectangle around the contour
Bounding rectangles are often used to highlight the regions of interest in the image. If this region of interest is a detected contour of a shape in the image, we can enclose it within a rectangle. There are two types of bounding rectangles that you may draw:
Straight Bounding Rectangle
Rotated Rectangle
For both types of bounding rectangles, their vertices are calculated using the coordinates in the contour list.
Straight Bounding Rectangle
A straight bounding rectangle is simply an upright rectangle that does not take into account the rotation of the object. Its vertices can be calculated using the cv2.boundingRect() function which calculates the vertices for the minimal up-right rectangle possible using the extreme coordinates in the contour list. The coordinates can then be drawn as rectangle using cv2.rectangle() function.
array – It is the Input gray-scale image or 2D point set from which the bounding rectangle is to be created
Returns:
x – It is X-coordinate of the top-left corner
y – It is Y-coordinate of the top-left corner
w – It is the width of the rectangle
h – It is the height of the rectangle
image1_copy = image1.copy()
# Convert to grayscale.
gray_scale = cv2.cvtColor(image1_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image.
contours, hierarchy = cv2.findContours(gray_scale, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
# Get the bounding rectangle
x, y, w, h = cv2.boundingRect(contours[1])
# Draw the rectangle around the object.
cv2.rectangle(image1_copy, (x, y), (x+w, y+h), (0, 255, 0), 3)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");
However, the bounding rectangle created is not a minimum area bounding rectangle often causing it to overlap with any other objects in the image. But what if the rectangle is rotated so that the area can be minimized to tightly fit the shape.
Rotated Rectangle
As the name suggests the rectangle drawn is rotated at an angle so that the area it occupies to enclose the contour is minimum. The function you can use to calculate the vertices of the rotated rectangle is cv2.minAreaRect(), which uses the contour point set to calculate the coordinates of the top left corner of the rectangle, its width, height, and the angle of rotation of the rectangle.
array – It is the Input gray-scale image or 2D point set from which the bounding rectangle is to be created
Returns:
retval – A tuple consisting of:
x,y coordinates of the top-left vertex
width, height of the rectangle
angle of rotation of the rectangle
Since the cv2.rectangle() function can only draw up-right rectangles we cannot use it to draw the rotated rectangle. Instead, we can calculate the 4 vertices of the rectangle using the cv2.boxPoints() function which takes the rect tuple as input. Once we have the vertices, the rectangle can be simply drawn using the cv2.drawContours() function.
image1_copy = image1.copy()
# Convert to grayscale
gray_scale = cv2.cvtColor(image1_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image
contours, hierarchy = cv2.findContours(gray_scale, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
# calculate the minimum area Bounding rect
rect = cv2.minAreaRect(contours[1])
# Check out the rect object
print(rect)
# convert the rect object to box points
box = cv2.boxPoints(rect).astype('int')
# Draw a rectangle around the object
cv2.drawContours(image1_copy,
This is the minimum area bounding rectangle possible. Let’s see how it compares to the straight bounding box.
# Draw the up-right rectangle
cv2.rectangle(image1_copy, (x, y), (x+w, y+h), (0,0, 255), 3)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");
Drawing Convex Hull
A convex hull is another useful way to represent the contour onto the image. The function cv2.convexHull() checks a curve for convexity defects and corrects it. Convex curves are curves that are bulged out. And if it is bulged inside (Concave), it is called convexity defects.
Finding the convex hull of a contour can be very useful when working with shape matching techniques. This is because the convex hull of a contour highlights its prominent features while discarding smaller variations in the shape.
points – Input 2D point set. This is a single contour.
clockwise – Orientation flag. If it is true, the output convex hull is oriented clockwise. Otherwise, it is oriented counter-clockwise. The assumed coordinate system has its X axis pointing to the right, and its Y axis pointing upwards.
returnPoints – Operation flag. In case of a matrix, when the flag is true, the function returns convex hull points. Otherwise, it returns indices of the convex hull points. By default it is True.
Returns:
hull – Output convex hull. It is either an integer vector of indices or vector of points. In the first case, the hull elements are 0-based indices of the convex hull points in the original array (since the set of convex hull points is a subset of the original point set). In the second case, hull elements are the convex hull points themselves.
image2 = cv2.imread('media/tree.jpg')
hull_img = image2.copy()
contour_img = image2.copy()
# Convert the image to gray-scale
gray = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)
# Create a binary thresholded image
_, binary = cv2.threshold(gray, 230, 255, cv2.THRESH_BINARY_INV)
# Find the contours from the thresholded image
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Since the image only has one contour, grab the first contour
cnt = contours[0]
# Get the required hull
hull = cv2.convexHull(cnt)
# draw the hull
cv2.drawContours(hull_img, [hull], 0 , (0,0,220), 3)
# draw the contour
cv2.drawContours(contour_img, [cnt], 0, (0,0,220), 3)
plt.figure(figsize=[18,18])
plt.subplot(131);plt.imshow(image2[:,:,::-1]);plt.title("Original Image");plt.axis('off')
plt.subplot(132);plt.imshow(contour_img[:,:,::-1]);plt.title("Contour");plt.axis('off');
plt.subplot(133);plt.imshow(hull_img[:,:,::-1]);plt.title("Convex Hull");plt.axis('off');
[optin-monster slug=”d8wgq6fdm5mppdb5fi99″]
Summary
In today’s post, we familiarized ourselves with many of the contour manipulation techniques. These manipulations help make contour detection an even more useful tool applicable to a wider variety of problems
We saw how you can filter out contours based on their size using the built-in max() and sorted() functions, allowing you to extract the largest contour or a list of contours sorted by size.
Then we learned how you can highlight contour detections with bounding rectangles of two types, the straight bounding rectangle and the rotated one.
Lastly, we learned about convex hulls and how you can find them for detected contours. A very handy technique that can prove to be useful for object detection with shape matching.
This sums up the second post in the series. In the next post, we’re going to learn various analytical techniques to analyze contours in order to classify and distinguish between different Objects.
So if you found this lesson useful, let me know in the comments and you can also support me and the Bleed AI team on patreon here.
If you need 1 on 1 Coaching in AI/computer vision regarding your project, or your career then you reach out to mepersonally here
Hire Us
Let our team of expert engineers and managers build your next big project using Bleeding Edge AI Tools & Technologies
So far in our Contour Detection 101 series, we have made significant progress unpacking many of the techniques and tools that you will need to build useful vision applications. In part 1, we learned the basics, how to detect and draw the contours, in part 2 we learned to do some contour manipulations.
Now in the third part of this series, we will be learning about analyzing contours. This is really important because by doing contour analysis you can actually recognize the object being detected and differentiate one contour from another. We will also explore how you can identify different properties of contours to retrieve useful information. Once you start analyzing the contours, you can do all sorts of cool things with them. The application below that I made, uses contour analysis to detect the shapes being drawn!
So if you haven’t seen any of the previous posts make sure you do check them out since in this part we are going to build upon what we have learned before so it will be helpful to have the basics straightened out if you are new to contour detection.
Alright, now we can get started with the Code.
Download Code
[optin-monster slug=”lrrdqnjzfuycvuetarn2″]
Import the Libraries
Let’s start by importing the required libraries.
import cv2
import math
import numpy as np
import pandas as pd
import transformations
import matplotlib.pyplot as plt
Read an Image
Next, let’s read an image containing a bunch of shapes.
# Read the image
image1 = cv2.imread('media/image.png')
# Display the image
plt.figure(figsize=[10,10])
plt.imshow(image1[:,:,::-1]);plt.title("Original Image");plt.axis("off");
Detect and draw Contours
Next, we will detect and draw external contours on the image usingcv2.findContours() and cv2.drawContours() functions that we have also discussed thoroughly in the previous posts.
image1_copy = image1.copy()
# Convert to grayscale
gray_scale = cv2.cvtColor(image1_copy,cv2.COLOR_BGR2GRAY)
# Find all contours in the image
contours, hierarchy = cv2.findContours(gray_scale, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# Draw all the contours.
contour_image = cv2.drawContours(image1_copy, contours, -1, (0,255,0), 3);
# Display the results.
plt.figure(figsize=[10,10])
plt.imshow(contour_image[:,:,::-1]);plt.title("Image Contours");plt.axis("off");
The result is a list of detected contours that can now be further analyzed for their properties. These properties are going to prove to be really useful when we build a vision application using contours. We will use them to provide us with valuable information about an object in the image and distinguish it from the other objects.
Below we will look at how you can retrieve some of these properties.
Image Moments
Image moments are like the weighted average of the pixel intensities in the image. They help calculate some features like the center of mass of the object, area of the object, etc. Finding image moments is a simple process in OpenCV which we can get by using the function cv2.moments() that returns a dictionary of various properties to use.
The values returned represent different kinds of image movements including raw moments, central moments, scale/rotation invariant moments, and so on.
For more information on image moments and how they are calculated, you can read this Wikipedia article. Below we will discuss how some of the image moments can be used to analyze the contours detected.
Find the center of a contour
Let’s start by finding the centroid of the object in the image using the contour’s image moments. The X and Y coordinates of the Centroid are given by two relations of the central image moments, Cx=M10/M00 and Cy=M01/M00.
# Calculate the X-coordinate of the centroid
cx = int(M['m10'] / M['m00'])
# Calculate the Y-coordinate of the centroid
cy = int(M['m01'] / M['m00'])
# Print the centroid point
print('Centroid: ({},{})'.format(cx,cy))
Centroid: (167,517)
Let’s repeat the process for the rest of the contours detected and draw a circle using cv2.circle() to indicate the centroids on the image.
image1_copy = image1.copy()
# Loop over the contours
for contour in contours:
# Get the image moments for the contour
M = cv2.moments(contour)
# Calculate the centroid
cx = int(M['m10'] / M['m00'])
cy = int(M['m01'] / M['m00'])
# Draw a circle to indicate the contour
cv2.circle(image1_copy,(cx,cy), 10, (0,0,255), -1)
# Display the results
plt.figure(figsize=[10,10])
plt.imshow(image1_copy[:,:,::-1]);plt.axis("off");
Finding Contour Area
We are already familiar with one way of finding the area of contour in the last post, using function cv2.contourArea().
# Select a contour
contour = contours[1]
# Get the area of the selected contour
area_method1 = cv2.contourArea(contour)
print('Area:',area_method1)
Area: 28977.5
Additionally, you can also find the area using the m00 moment of the contour which contains the contour’s area.
# get selected contour moments
M = cv2.moments(contour)
# Get the moment containing the Area
area_method2 = M['m00']
print('Area:',area_method2)
Area: 28977.5
As you can see, both of the methods give the same result.
Contour Properties
When building an application using contours, information about the properties of a contour is vital. These properties are often invariant to one or more transformations such as translation, scaling, and rotation. Below, we will have a look at some of these properties.
Let’s start by detecting the external contours of an image.
# Read the image
image4 = cv2.imread('media/sword.jpg')
# Create a copy
image4_copy = image4.copy()
# Convert to gray-scale
imageGray = cv2.cvtColor(image4_copy,cv2.COLOR_BGR2GRAY)
# create a binary thresholded image
_, binary = cv2.threshold(imageGray, 220, 255, cv2.THRESH_BINARY_INV)
# Detect and draw external contour
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# Select a contour
contour = contours[0]
# Draw the selected contour
cv2.drawContours(image4_copy, contour, -1, (0,255,0), 3)
# Display the result
plt.figure(figsize=[10,10])
plt.imshow(image4_copy[:,:,::-1]);plt.title("Sword Contour");plt.axis("off");
Now using a custom transform() function from the transformation.py module which you will find included with the code for this post, we can conveniently apply and display different transformations to an image.
Applied Translation of x: 44, y: 30 Applied rotation of angle: 80 Image resized to: 95.0
Aspect ratio
Aspect ratio is the ratio of width to height of the bounding rectangle of an object. It can be calculated as AR=width/height. This value is always invariant to translation.
# Get the up-right bounding rectangle for the image
x,y,w,h = cv2.boundingRect(contour)
# calculate the aspect ratio
aspect_ratio = float(w)/h
print("Aspect ratio intitially {}".format(aspect_ratio))
# Apply translation to the image and get its detected contour
modified_contour = transformations.transform(translate=True)
# Get the bounding rectangle for the detected contour
x,y,w,h = cv2.boundingRect(modified_contour)
# Calculate the aspect ratio for the modified contour
aspect_ratio = float(w)/h
print("Aspect ratio After Modification {}".format(aspect_ratio))
Aspect ratio initially 0.9442231075697212 Applied Translation of x: -45 , y: -49 Aspect ratio After Modification 0.9442231075697212
Extent
Another useful property is the extent of a contour which is the ratio of contour area to its bounding rectangle area. Extent is invariant to Translation & Scaling.
To find the extend we start by calculating the contour area for the selected contour using the function cv2.contourArea(). Next, the bounding rectangle is found using cv2.boundingRect(). The area of the bounding rectangle is calculated using rectarea=width×height. Finally, the extent is then calculated as extent=contourarea/rectarea.
# Calculate the area for the contour
original_area = cv2.contourArea(contour)
# find the bounding rectangle for the contour
x,y,w,h = cv2.boundingRect(contour)
# calculate the area for the bounding rectangle
rect_area = w*h
# calcuate the extent
extent = float(original_area)/rect_area
print("Extent intitially {}".format(extent))
# apply scaling and translation to the image and get the contour
modified_contour = transformations.transform(translate=True,scale = True)
# Get the area of modified contour
modified_area = cv2.contourArea(modified_contour)
# Get the bounding rectangle
x,y,w,h = cv2.boundingRect(modified_contour)
# Calculate the area for the bounding rectangle
modified_rect_area = w*h
# calcuate the extent
extent = float(modified_area)/modified_rect_area
print("Extent After Modification {}".format(extent))
Extent intitially 0.2404054667406324 Applied Translation of x: 38 , y: 44 Image resized to: 117.0% Extent After Modification 0.24218788234718347
Equivalent Diameter
Equivalent Diameter is the diameter of the circle whose area is the same as the contour area. It is Invariant to Translation & Rotation. The equivalent diameter can be calculated by first getting the area of contour with cv2.boundingRect(), the area of the circle is given by area=2×π×d2/4 where d is the diameter of the circle.
So to find the diameter we just have to make d the subject in the above equation, giving us: d= √(4×rectArea/π).
# Calculate the diameter
equi_diameter = np.sqrt(4*original_area/np.pi)
print("Equi diameter intitially {}".format(equi_diameter))
# Apply rotation and transformation
modified_contour = transformations.transform(rotate= True)
# Get the area of modified contour
modified_area = cv2.contourArea(modified_contour)
# Calculate the diameter
equi_diameter = np.sqrt(4*modified_area/np.pi)
print("Equi diameter After Modification {}".format(equi_diameter))
Equi diameter intitially 134.93924087995146 Applied Translation of x: -39 , y: 38 Applied rotation of angle: 38 Equi diameter After Modification 135.06184863765444
Orientation
Orientation is simply the angle at which an object is rotated.
# Rotate and translate the contour
modified_contour = transformations.transform(translate=True,rotate= True,display = True)
Applied Translation of x: 48 , y: -37 Applied rotation of angle: 176
Now Let’s take a look at an elliptical angle on the sword contour above
# Fit and ellipse onto the contour similarly to minimum area rectangle
(x,y),(MA,ma),angle = cv2.fitEllipse(modified_contour)
# Print the angle of rotation of ellipse
print("Elliptical Angle is {}".format(angle))
Elliptical Angle is 46.882904052734375
Below method also gives the angle of the contour by fitting a rotated box instead of an ellipse
(x,y),(w,mh),angle = cv2.minAreaRect(modified_contour)
print("RotatedRect Angle is {}".format(angle))
RotatedRect Angle is 45.0
Note:Don’t be confused by why all three angles are showing different results, they all calculate angles differently, for e.g ellipse fits an ellipse and then calculates the angle that an ellipse makes, similarly the rotated rectangle calculates the angle the rectangle makes. For triggering decisions based on the calculated angle you would first need to find what angle the respective method is making at the given orientations of the object.
Hu moments
Hu moments are a set of 7 numbers calculated using the central moments. What makes these 7 moments special is the fact that out of these 7 moments, the first 6 of the Hu moments are invariant to translation, scaling, rotation and reflection. The 7th Hu moment is also invariant to these transformations, except that it changes its sign in case of reflection. Below we will calculate the Hu moments for the sword contour, using the moments of the contour.
You can read this paper if you want to know more about hu-moments and how they are calculated.
# Calculate moments
M = cv2.moments(contour)
# Calculate Hu Moments
hu_M = cv2.HuMoments(M)
print(hu_M)
As you can see the different hu-moments have varying ranges (e.g. compare hu-moment 1 and 7) so to make the Hu-moments more comparable with each other, we will transform them to log-scale and bring them all to the same range.
# Log scale hu moments
for i in range(0,7):
hu_M[i] = -1* math.copysign(1.0, hu_M[i]) * math.log10(abs(hu_M[i]))
df = pd.DataFrame(hu_M,columns=['Hu-moments of original Image'])
df
Next up let’s apply transformations to the image and find the Hu-moments again.
# Apply translation to the image and get its detected contour
modified_contour = transformations.transform(translate = True, scale = True, rotate = True)
Applied Translation of x: -31 , y: 48 Applied rotation of angle: 122 Image resized to: 87.0%
# Calculate moments
M_modified = cv2.moments(modified_contour)
# Calculate Hu Moments
hu_Modified = cv2.HuMoments(M_modified)
# Log scale hu moments
for i in range(0,7):
hu_Modified[i] = -1* math.copysign(1.0, hu_Modified[i]) * math.log10(abs(hu_Modified[i]))
df['Hu-moments of Modified Image'] = hu_Modified
df
The difference is minimal because of the invariance of Hu-moments to the applied transformations.
[optin-monster slug=”d8wgq6fdm5mppdb5fi99″]
Summary
In this post, we saw how useful contour detection can be when you analyze the detected contour for its properties, enabling you to build applications capable of detecting and identifying objects in an image.
We learned how image moments can provide us useful information about a contour such as the center of a contour or the area of contour.
We also learned how to calculate different contour properties invariant to different transformations such as rotation, translation, and scaling.
Lastly, we also explored seven unique image moments called Hu-moments which are really helpful for object detection using contours since they are invariant to translation, scaling, rotation, and reflection at once.
This concludes the third part of the series. In the next and final part of the series, we will be building a Vehicle Detection Application using many of the techniques we have learned in this series.
You can reach out to me personally for a 1 on 1 consultation session in AI/computer vision regarding your project. Our talented team of vision engineers will help you every step of the way. Get on a call with me directlyhere.
Ready to seriously dive into State of the Art AI & Computer Vision? Then Sign up for these premium Courses by Bleed AI
Vehicle detection has been a challenging part of building intelligent traffic management systems. Such systems are critical for addressing the ever-increasing number of vehicles on road networks that cannot keep up with the pace of increasing traffic. Today many methods that deal with this problem use either traditional computer vision or complex deep learning models.
Popular computer vision techniques include vehicle detection using optical flow, but in this tutorial, we are going to perform vehicle detection using another traditional computer vision technique that utilizes background subtraction and contour detection to detect vehicles. This means you won’t have to spend hundreds of hours in data collection or annotation for building deep learning models, which can be tedious, to say the least. Not to mention, the computation power required to train the models.
This post is the fourth and final part of our Contour Detection 101 series. All 4 posts in the series are titled as:
Vehicle Detection with OpenCV using Contours + Background Subtraction (This Post)
So if you are new to the series and unfamiliar with contour detection, make sure you check them out!
In part 1 of the series, we learned the basics, how to detect and draw the contours, in part 2 we learned to do some contour manipulations and in the third part, we analyzed the detected contours for their properties to perform tasks like object detection. Combining these techniques with background subtraction will enable us to build a useful application that detects vehicles on a road. And not just that but you can use the same principles that you learn in this tutorial to create other motion detection applications.
So let’s dive into how vehicle detection with background subtraction works.
Import the Libraries
Let’s First start by importing the libraries.
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Background subtraction is a simple yet effective technique to extract objects from an image/video. Consider a highway on which cars are moving, and you want to extract each car. One easy way can be that you take a picture of the highway with the cars (called foreground image) and you also have an image saved in which the highway does not contain any cars (background image) so you subtract the background image from the foreground to get the segmented mask of the cars and then use that mask to extract the cars.
But in many cases you don’t have a clear background image, an example of this can be a highway that is always busy, or maybe a walking destination that is always crowded. So in those cases, you can subtract the background by other means, for example, in the case of a video you can detect the movement of the object, so the objects which move can be foreground and the other part that remain static can be the background.
Several algorithms have been invented for this purpose. OpenCV has implemented a few such algorithms which are very easy to use. Let’s see one of them.
history (optional) – It is the length of the history. Its default value is 500.
varThreshold (optional) – It is the threshold on the squared distance between the pixel and the model to decide whether a pixel is well described by the background model. It does not affect the background update and its default value is 16.
detectShadows (optional) – It is a boolean that determines whether the algorithm will detect and mark shadows or not. It marks shadows in gray color. Its default value is True. It decreases the speed a bit, so if you do not need this feature, set the parameter to false.
Returns:
object – It is the MOG2 Background Subtractor.
# load a video
cap = cv2.VideoCapture('media/videos/vtest.avi')
# you can optionally work on the live web cam
# cap = cv2.VideoCapture(0)
# create the background object, you can choose to detect shadows or not (if True they will be shown as gray)
backgroundobject = cv2.createBackgroundSubtractorMOG2( history = 2, detectShadows = True )
while(1):
ret, frame = cap.read()
if not ret:
break
# apply the background object on each frame
fgmask = backgroundobject.apply(frame)
# also extracting the real detected foreground part of the image (optional)
real_part = cv2.bitwise_and(frame,frame,mask=fgmask)
# making fgmask 3 channeled so it can be stacked with others
fgmask_3 = cv2.cvtColor(fgmask, cv2.COLOR_GRAY2BGR)
# Stack all three frames and show the image
stacked = np.hstack((fgmask_3,frame,real_part))
cv2.imshow('All three',cv2.resize(stacked,None,fx=0.65,fy=0.65))
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
Output:
The second frame is the original video, on the left we have the background subtraction result with shadows, while on the right we have the foreground part produced using the background subtraction mask.
Creating the Vehicle Detection Application
Alright once we have our background subtraction method ready, we can build our final application!
Here’s the breakdown of the steps we need to perform the complete background Subtraction based contour detection.
1) Start by loading the video using the function cv2.VideoCapture() and create a background subtractor object using the function cv2.createBackgroundSubtractorMOG2().
3) Next, we will apply thresholding on the mask using the function cv2.threshold() to get rid of shadows and then perform Erosion and Dilation to improve the mask further using the functions cv2.erode() and cv2.dilate().
4) Then we will use the function cv2.findContours() to detect the contours on the mask image and convert the contour coordinates into bounding box coordinates for each car in the frame using the function cv2.boundingRect(). We will also check the area of the contour using cv2.contourArea() to make sure it is greater than a threshold for a car contour.
5) After that we will use the functions cv2.rectangle() and cv2.putText() to draw and label the bounding boxes on each frame and extract the foreground part of the video with the help of the segmented mask using the function cv2.bitwise_and().
# load a video
video = cv2.VideoCapture('media/videos/carsvid.wmv')
# You can set custom kernel size if you want.
kernel = None
# Initialize the background object.
backgroundObject = cv2.createBackgroundSubtractorMOG2(detectShadows = True)
while True:
# Read a new frame.
ret, frame = video.read()
# Check if frame is not read correctly.
if not ret:
# Break the loop.
break
# Apply the background object on the frame to get the segmented mask.
fgmask = backgroundObject.apply(frame)
#initialMask = fgmask.copy()
# Perform thresholding to get rid of the shadows.
_, fgmask = cv2.threshold(fgmask, 250, 255, cv2.THRESH_BINARY)
#noisymask = fgmask.copy()
# Apply some morphological operations to make sure you have a good mask
fgmask = cv2.erode(fgmask, kernel, iterations = 1)
fgmask = cv2.dilate(fgmask, kernel, iterations = 2)
# Detect contours in the frame.
contours, _ = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Create a copy of the frame to draw bounding boxes around the detected cars.
frameCopy = frame.copy()
# loop over each contour found in the frame.
for cnt in contours:
# Make sure the contour area is somewhat higher than some threshold to make sure its a car and not some noise.
if cv2.contourArea(cnt) > 400:
# Retrieve the bounding box coordinates from the contour.
x, y, width, height = cv2.boundingRect(cnt)
# Draw a bounding box around the car.
cv2.rectangle(frameCopy, (x , y), (x + width, y + height),(0, 0, 255), 2)
# Write Car Detected near the bounding box drawn.
cv2.putText(frameCopy, 'Car Detected', (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0,255,0), 1, cv2.LINE_AA)
# Extract the foreground from the frame using the segmented mask.
foregroundPart = cv2.bitwise_and(frame, frame, mask=fgmask)
# Stack the original frame, extracted foreground, and annotated frame.
stacked = np.hstack((frame, foregroundPart, frameCopy))
# Display the stacked image with an appropriate title.
cv2.imshow('Original Frame, Extracted Foreground and Detected Cars', cv2.resize(stacked, None, fx=0.5, fy=0.5))
#cv2.imshow('initial Mask', initialMask)
#cv2.imshow('Noisy Mask', noisymask)
#cv2.imshow('Clean Mask', fgmask)
# Wait until a key is pressed.
# Retreive the ASCII code of the key pressed
k = cv2.waitKey(1) & 0xff
# Check if 'q' key is pressed.
if k == ord('q'):
# Break the loop.
break
# Release the VideoCapture Object.
video.release()
# Close the windows
cv2.destroyAllWindows()
Output:
This seems to have worked out well, that too without having to train large-scale Deep learning models!
There are many other background subtraction algorithms in OpenCV that you can use. Check out here and here for further details about them.
Summary
Vehicle Detection is a popular computer vision problem. This post explored how traditional machine vision tools can still be utilized to build applications that can effectively deal with modern vision challenges.
We used a popular background/foreground segmentation technique called background subtraction to isolate our regions of interest from the image.
We also saw how contour detection can prove to be useful when dealing with vision problems. The pre-processing and post-processing that can be used to filter out the noise in the detected contours.
Although these techniques can be robust, they are not as generalizable as Deep learning models so it’s important to put more focus on deployment conditions and possible variations when building vision applications with such techniques.
This post concludes the four-part series on contour detection. If you enjoyed this post and followed the rest of the series do let me know in the comments and you can also support me and the Bleed AI team on patreon here.
If you need 1 on 1 Coaching in AI/computer vision regarding your project, or your career then you reach out to mepersonally here
Hire Us
Let our team of expert engineers and managers build your next big project using Bleeding Edge AI Tools & Technologies
Convolutional Neural Networks (CNN) are great for image data and Long-Short Term Memory (LSTM) networks are great when working with sequence data but when you combine both of them, you get the best of both worlds and you solve difficult computer vision problems like video classification.
In this tutorial, we’ll learn to implement human action recognition on videos using a Convolutional Neural Network combined with a Long-Short Term Memory Network. We’ll actually be using two different architectures and approaches in TensorFlow to do this. In the end, we’ll take the best-performing model and perform predictions with it on youtube videos.
Before I start with the code, let me cover some theories on video classification and different approaches that are available for it.
Image Classification
You may already be familiar with an image classification problem, where, you simply pass an image to the classifier (either a trained Deep Neural Network (CNN or an MLP) or a classical classifier) and get the class predictions out of it.
But what if you have a video? What will happen then?
Before we talk about how to go about dealing with videos, let’s just discuss what videos are exactly.
But First What Exactly Videos are?
Well, so it’s no secret that a video is just a sequence of multiple still images (aka. frames) that are updated really fast creating the appearance of a motion. Consider the video (converted into .gif format) below of a cat jumping on a bookshelf, it is just a combination of 15 different still images that are being updated one after the other.
Now that we understand what videos are, let’s take a look at a number of approaches that we can use to do video classification.
Approach 1: Single-Frame Classification
The simplest and most basic way of classifying actions in a video can be using an image classifier on each frame of the video and classify action in each frame independently. So if we implement this approach for a video of a person doing a backflip, we will get the following results.
The classifier predicts Falling in some frames instead of Backflipping because this approach ignores the temporal relation of the frames sequence. And even if a person looks at those frames independently he may think that the person is Falling.
Now a simple way to get a final prediction for the video is to consider the most frequent one which can work in simple scenarios but is Falling in our case and is not correct. So another way to go about this is to take an average of the probabilities of predictions and get a more robust final prediction.
You should also check another Video Classification and Human Activity Recognition tutorial I had published a while back, in which I had discussed a number of other approaches too and implemented this one using a single-frame CNN with moving averages and it had worked fine for a relatively simpler problem.
But as mentioned before, this approach is not effective, because it does not take into account the temporal aspect of the data.
Approach 2: Late Fusion
Another slightly different approach is late fusion, in which after performing predictions on each frame independently, the classification results are passed to a fusion layer that merges all the information and makes the prediction. This approach also leverages the temporal information of the data.
This approach does give decent results but is still not powerful enough. Now before moving to the next approach let’s discuss what Convolutional Neural Networks are. So that you get an idea of what that black box named image classifier was, that I was using in the images.
Convolutional Neural Network (CNN)
A Convolutional Neural Network (CNN or ConvNet) is a type of deep neural network that is specifically designed to work with image data and excels when it comes to analyzing the images and making predictions on them.
It works with kernels (called filters) that go over the image and generates feature maps (that represent whether a certain feature is present at a location in the image or not) and initially it generates few feature maps and as we go deeper in the network the number of feature maps is increased and the size of maps is decreased using pooling operations without losing critical information.
Each layer of a ConvNet learns features of increasing complexity which means, for example, the first layer may learn to detect edges and corners, while the last layer may learn to recognize humans in different postures.
Now let’s get back to discussing other approaches for video classification.
Approach 3: Early Fusion
Another approach of video classification is early fusion, in which all the information is merged at the beginning of the network, unlike late fusion which merges the information in the end. This is a powerful approach but still has its own limitations.
Approach 4: Using 3D CNN’s (aka. Slow Fusion)
Another option is to use a 3D Convolutional Network, where the temporal and spatial information are merged slowly throughout the whole network that is why it’s called Slow Fusion. But a disadvantage of this approach is that it is computationally really expensive so it is pretty slow.
Approach 5: Using Pose Detection and LSTM
Another method is to use a pose detection network on the video to get the landmark coordinates of the person for each frame in the video. And then feed the landmarks to an LSTM Network to predict the activity of the person.
There are already a lot of efficient pose detectors out there that can be used for this approach. But a disadvantage of using this approach is that you discard all the information other than the landmarks, like the environment information can be very useful, for example for playing football action category the stadium and uniform info can help the model a lot in predicting the action accurately.
Before going to the approach that we will implement in this tutorial, let’s briefly discuss what are Long Short Term Memory (LSTM) networks, as we will be using them in the approach.
Long Short Term Memory (LSTM)
An LSTM network is specifically designed to work with a data sequence as it takes into consideration all of the previous inputs while generating an output. LSTMs are actually a type of neural network called Recurrent Neural Network, but RNNs are not known to be effective for dealing with the Long term dependencies in the input sequence because of a problem called the Vanishing gradient problem.
LSTMs were developed to overcome the vanishing gradient and so an LSTM cell can remember context for long input sequences.
Many-to-one LSTM network
This makes an LSTM more capable of solving problems involving sequential data such as time series prediction, speech recognition, language translation, or music composition. But for now, we will only explore the role of LSTMs in developing better action recognition models.
Now let’s move on towards the approach we will implement in this tutorial to build an Action Recognizer. We will use a Convolution Neural Network (CNN) + Long Short Term Memory (LSTM) Network to perform Action Recognition while utilizing the Spatial-temporal aspect of the videos.
Approach 6: CNN + LSTM
We will be using a CNN to extract spatial features at a given time step in the input sequence (video) and then an LSTM to identify temporal relations between frames.
The two architectures that we will be using to use CNN along with LSTM are:
ConvLSTM
LRCN
Both of these approaches can be used using TensorFlow. This tutorial also has a video version as well, that you can go and watch for a more detailed overview of the code.
Alright, so without further ado, let’s get started.
Import the Libraries
We will start by installing and importing the required libraries.
# Install the required libraries.
!pip install pafy youtube-dl moviepy
# Import the required libraries.
import os
import cv2
import pafy
import math
import random
import numpy as np
import datetime as dt
import tensorflow as tf
from collections import deque
import matplotlib.pyplot as plt
from moviepy.editor import *
%matplotlib inline
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import *
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.utils import plot_model
And will set Numpy, Python, and Tensorflow seeds to get consistent results on every execution.
Step 1: Download and Visualize the Data with its Labels
In the first step, we will download and visualize the data along with labels to get an idea about what we will be dealing with. We will be using the UCF50 – Action Recognition Dataset, consisting of realistic videos taken from youtube which differentiates this data set from most of the other available action recognition data sets as they are not realistic and are staged by actors. The Dataset contains:
50 Action Categories
25 Groups of Videos per Action Category
133 Average Videos per Action Category
199 Average Number of Frames per Video
320 Average Frames Width per Video
240 Average Frames Height per Video
26 Average Frames Per Seconds per Video
Let’s download and extract the dataset.
# Discard the output of this cell.
%%capture
# Downlaod the UCF50 Dataset
!wget --no-check-certificate https://www.crcv.ucf.edu/data/UCF50.rar
#Extract the Dataset
!unrar x UCF50.rar
For visualization, we will pick 20 random categories from the dataset and a random video from each selected category and will visualize the first frame of the selected videos with their associated labels written. This way we’ll be able to visualize a subset ( 20 random videos ) of the dataset.CodeText
# Create a Matplotlib figure and specify the size of the figure.
plt.figure(figsize = (20, 20))
# Get the names of all classes/categories in UCF50.
all_classes_names = os.listdir('UCF50')
# Generate a list of 20 random values. The values will be between 0-50,
# where 50 is the total number of class in the dataset.
random_range = random.sample(range(len(all_classes_names)), 20)
# Iterating through all the generated random values.
for counter, random_index in enumerate(random_range, 1):
# Retrieve a Class Name using the Random Index.
selected_class_Name = all_classes_names[random_index]
# Retrieve the list of all the video files present in the randomly selected Class Directory.
video_files_names_list = os.listdir(f'UCF50/{selected_class_Name}')
# Randomly select a video file from the list retrieved from the randomly selected Class Directory.
selected_video_file_name = random.choice(video_files_names_list)
# Initialize a VideoCapture object to read from the video File.
video_reader = cv2.VideoCapture(f'UCF50/{selected_class_Name}/{selected_video_file_name}')
# Read the first frame of the video file.
_, bgr_frame = video_reader.read()
# Release the VideoCapture object.
video_reader.release()
# Convert the frame from BGR into RGB format.
rgb_frame = cv2.cvtColor(bgr_frame, cv2.COLOR_BGR2RGB)
# Write the class name on the video frame.
cv2.putText(rgb_frame, selected_class_Name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
# Display the frame.
plt.subplot(5, 4, counter);plt.imshow(rgb_frame);plt.axis('off')
Step 2: Preprocess the Dataset
Next, we will perform some preprocessing on the dataset. First, we will read the video files from the dataset and resize the frames of the videos to a fixed width and height, to reduce the computations and normalized the data to range [0-1] by dividing the pixel values with 255, which makes convergence faster while training the network.
But first, let’s initialize some constants.
# Specify the height and width to which each video frame will be resized in our dataset.
IMAGE_HEIGHT , IMAGE_WIDTH = 64, 64
# Specify the number of frames of a video that will be fed to the model as one sequence.
SEQUENCE_LENGTH = 20
# Specify the directory containing the UCF50 dataset.
DATASET_DIR = "UCF50"
# Specify the list containing the names of the classes used for training. Feel free to choose any set of classes.
CLASSES_LIST = ["WalkingWithDog", "TaiChi", "Swing", "HorseRace"]
Note:The IMAGE_HEIGHT, IMAGE_WIDTH and SEQUENCE_LENGTH constants can be increased for better results, although increasing the sequence length is only effective to a certain point, and increasing the values will result in the process being more computationally expensive.
Create a Function to Extract, Resize & Normalize Frames
We will create a function frames_extraction() that will create a list containing the resized and normalized frames of a video whose path is passed to it as an argument. The function will read the video file frame by frame, although not all frames are added to the list as we will only need an evenly distributed sequence length of frames.
def frames_extraction(video_path):
'''
This function will extract the required frames from a video after resizing and normalizing them.
Args:
video_path: The path of the video in the disk, whose frames are to be extracted.
Returns:
frames_list: A list containing the resized and normalized frames of the video.
'''
# Declare a list to store video frames.
frames_list = []
# Read the Video File using the VideoCapture object.
video_reader = cv2.VideoCapture(video_path)
# Get the total number of frames in the video.
video_frames_count = int(video_reader.get(cv2.CAP_PROP_FRAME_COUNT))
# Calculate the the interval after which frames will be added to the list.
skip_frames_window = max(int(video_frames_count/SEQUENCE_LENGTH), 1)
# Iterate through the Video Frames.
for frame_counter in range(SEQUENCE_LENGTH):
# Set the current frame position of the video.
video_reader.set(cv2.CAP_PROP_POS_FRAMES, frame_counter * skip_frames_window)
# Reading the frame from the video.
success, frame = video_reader.read()
# Check if Video frame is not successfully read then break the loop
if not success:
break
# Resize the Frame to fixed height and width.
resized_frame = cv2.resize(frame, (IMAGE_HEIGHT, IMAGE_WIDTH))
# Normalize the resized frame by dividing it with 255 so that each pixel value then lies between 0 and 1
normalized_frame = resized_frame / 255
# Append the normalized frame into the frames list
frames_list.append(normalized_frame)
# Release the VideoCapture object.
video_reader.release()
# Return the frames list.
return frames_list
Create a Function for Dataset Creation
Now we will create a function create_dataset() that will iterate through all the classes specified in the CLASSES_LIST constant and will call the function frame_extraction() on every video file of the selected classes and return the frames (features), class index ( labels), and video file path (video_files_paths).
def create_dataset():
'''
This function will extract the data of the selected classes and create the required dataset.
Returns:
features: A list containing the extracted frames of the videos.
labels: A list containing the indexes of the classes associated with the videos.
video_files_paths: A list containing the paths of the videos in the disk.
'''
# Declared Empty Lists to store the features, labels and video file path values.
features = []
labels = []
video_files_paths = []
# Iterating through all the classes mentioned in the classes list
for class_index, class_name in enumerate(CLASSES_LIST):
# Display the name of the class whose data is being extracted.
print(f'Extracting Data of Class: {class_name}')
# Get the list of video files present in the specific class name directory.
files_list = os.listdir(os.path.join(DATASET_DIR, class_name))
# Iterate through all the files present in the files list.
for file_name in files_list:
# Get the complete video path.
video_file_path = os.path.join(DATASET_DIR, class_name, file_name)
# Extract the frames of the video file.
frames = frames_extraction(video_file_path)
# Check if the extracted frames are equal to the SEQUENCE_LENGTH specified above.
# So ignore the vides having frames less than the SEQUENCE_LENGTH.
if len(frames) == SEQUENCE_LENGTH:
# Append the data to their repective lists.
features.append(frames)
labels.append(class_index)
video_files_paths.append(video_file_path)
# Converting the list to numpy arrays
features = np.asarray(features)
labels = np.array(labels)
# Return the frames, class index, and video file path.
return features, labels, video_files_paths
Now we will utilize the function create_dataset() created above to extract the data of the selected classes and create the required dataset.
# Create the dataset.
features, labels, video_files_paths = create_dataset()
Extracting Data of Class: WalkingWithDog
Extracting Data of Class: TaiChi
Extracting Data of Class: Swing
Extracting Data of Class: HorseRace
Now we will convert labels (class indexes) into one-hot encoded vectors.
# Using Keras's to_categorical method to convert labels into one-hot-encoded vectors
one_hot_encoded_labels = to_categorical(labels)
Step 3: Split the Data into Train and Test Set
As of now, we have the required features (a NumPy array containing all the extracted frames of the videos) and one_hot_encoded_labels (also a Numpy array containing all class labels in one hot encoded format). So now, we will split our data to create training and testing sets. We will also shuffle the dataset before the split to avoid any bias and get splits representing the overall distribution of the data.
# Split the Data into Train ( 75% ) and Test Set ( 25% ).
features_train, features_test, labels_train, labels_test = train_test_split(features, one_hot_encoded_labels, test_size = 0.25, shuffle = True, random_state = seed_constant)
Step 4: Implement the ConvLSTM Approach
In this step, we will implement the first approach by using a combination of ConvLSTM cells. A ConvLSTM cell is a variant of an LSTM network that contains convolutions operations in the network. it is an LSTM with convolution embedded in the architecture, which makes it capable of identifying spatial features of the data while keeping into account the temporal relation.
For video classification, this approach effectively captures the spatial relation in the individual frames and the temporal relation across the different frames. As a result of this convolution structure, the ConvLSTM is capable of taking in 3-dimensional input (width, height, num_of_channels) whereas a simple LSTM only takes in 1-dimensional input hence an LSTM is incompatible for modeling Spatio-temporal data on its own.
To construct the model, we will use Keras ConvLSTM2D recurrent layers. The ConvLSTM2D layer also takes in the number of filters and kernel size required for applying the convolutional operations. The output of the layers is flattened in the end and is fed to the Dense layer with softmax activation which outputs the probability of each action category.
We will also use MaxPooling3D layers to reduce the dimensions of the frames and avoid unnecessary computations and Dropout layers to prevent overfitting the model on the data. The architecture is a simple one and has a small number of trainable parameters. This is because we are only dealing with a small subset of the dataset which does not require a large-scale model.
def create_convlstm_model():
'''
This function will construct the required convlstm model.
Returns:
model: It is the required constructed convlstm model.
'''
# We will use a Sequential model for model construction
model = Sequential()
# Define the Model Architecture.
########################################################################################################################
model.add(ConvLSTM2D(filters = 4, kernel_size = (3, 3), activation = 'tanh',data_format = "channels_last",
recurrent_dropout=0.2, return_sequences=True, input_shape = (SEQUENCE_LENGTH,
IMAGE_HEIGHT, IMAGE_WIDTH, 3)))
model.add(MaxPooling3D(pool_size=(1, 2, 2), padding='same', data_format='channels_last'))
model.add(TimeDistributed(Dropout(0.2)))
model.add(ConvLSTM2D(filters = 8, kernel_size = (3, 3), activation = 'tanh', data_format = "channels_last",
recurrent_dropout=0.2, return_sequences=True))
model.add(MaxPooling3D(pool_size=(1, 2, 2), padding='same', data_format='channels_last'))
model.add(TimeDistributed(Dropout(0.2)))
model.add(ConvLSTM2D(filters = 14, kernel_size = (3, 3), activation = 'tanh', data_format = "channels_last",
recurrent_dropout=0.2, return_sequences=True))
model.add(MaxPooling3D(pool_size=(1, 2, 2), padding='same', data_format='channels_last'))
model.add(TimeDistributed(Dropout(0.2)))
model.add(ConvLSTM2D(filters = 16, kernel_size = (3, 3), activation = 'tanh', data_format = "channels_last",
recurrent_dropout=0.2, return_sequences=True))
model.add(MaxPooling3D(pool_size=(1, 2, 2), padding='same', data_format='channels_last'))
#model.add(TimeDistributed(Dropout(0.2)))
model.add(Flatten())
model.add(Dense(len(CLASSES_LIST), activation = "softmax"))
########################################################################################################################
# Display the models summary.
model.summary()
# Return the constructed convlstm model.
return model
Now we will utilize the function create_convlstm_model() created above, to construct the required convlstm model.
# Construct the required convlstm model.
convlstm_model = create_convlstm_model()
# Display the success message.
print("Model Created Successfully!")
Check Model’s Structure:
Now we will use the plot_model() function, to check the structure of the constructed model, this is helpful while constructing a complex network and making that the network is created correctly.
# Plot the structure of the contructed model.
plot_model(convlstm_model, to_file = 'convlstm_model_structure_plot.png', show_shapes = True, show_layer_names = True)
Step 4.2: Compile & Train the Model
Next, we will add an early stopping callback to prevent overfitting and start the training after compiling the model.
# Create an Instance of Early Stopping Callback
early_stopping_callback = EarlyStopping(monitor = 'val_loss', patience = 10, mode = 'min', restore_best_weights = True)
# Compile the model and specify loss function, optimizer and metrics values to the model
convlstm_model.compile(loss = 'categorical_crossentropy', optimizer = 'Adam', metrics = ["accuracy"])
# Start training the model.
convlstm_model_training_history = convlstm_model.fit(x = features_train, y = labels_train, epochs = 50, batch_size = 4,shuffle = True, validation_split = 0.2, callbacks = [early_stopping_callback])
Evaluate the Trained Model
After training, we will evaluate the model on the test set.
# Evaluate the trained model.
model_evaluation_history = convlstm_model.evaluate(features_test, labels_test)
Now we will save the model to avoid training it from scratch every time we need the model.
# Get the loss and accuracy from model_evaluation_history.
model_evaluation_loss, model_evaluation_accuracy = model_evaluation_history
# Define the string date format.
# Get the current Date and Time in a DateTime Object.
# Convert the DateTime object to string according to the style mentioned in date_time_format string.
date_time_format = '%Y_%m_%d__%H_%M_%S'
current_date_time_dt = dt.datetime.now()
current_date_time_string = dt.datetime.strftime(current_date_time_dt, date_time_format)
# Define a useful name for our model to make it easy for us while navigating through multiple saved models.
model_file_name = f'convlstm_model___Date_Time_{current_date_time_string}___Loss_{model_evaluation_loss}___Accuracy_{model_evaluation_accuracy}.h5'
# Save your Model.
convlstm_model.save(model_file_name)
Step 4.3: Plot Model’s Loss & Accuracy Curves
Now we will create a function plot_metric() to visualize the training and validation metrics. We already have separate metrics from our training and validation steps so now we just have to visualize them.
def plot_metric(model_training_history, metric_name_1, metric_name_2, plot_name):
'''
This function will plot the metrics passed to it in a graph.
Args:
model_training_history: A history object containing a record of training and validation
loss values and metrics values at successive epochs
metric_name_1: The name of the first metric that needs to be plotted in the graph.
metric_name_2: The name of the second metric that needs to be plotted in the graph.
plot_name: The title of the graph.
'''
# Get metric values using metric names as identifiers.
metric_value_1 = model_training_history.history[metric_name_1]
metric_value_2 = model_training_history.history[metric_name_2]
# Construct a range object which will be used as x-axis (horizontal plane) of the graph.
epochs = range(len(metric_value_1))
# Plot the Graph.
plt.plot(epochs, metric_value_1, 'blue', label = metric_name_1)
plt.plot(epochs, metric_value_2, 'red', label = metric_name_2)
# Add title to the plot.
plt.title(str(plot_name))
# Add legend to the plot.
plt.legend()
Now we will utilize the function plot_metric() created above, to visualize and understand the metrics.
# Visualize the training and validation loss metrices.
plot_metric(convlstm_model_training_history, 'loss', 'val_loss', 'Total Loss vs Total Validation Loss')
# Visualize the training and validation accuracy metrices.
plot_metric(convlstm_model_training_history, 'accuracy', 'val_accuracy', 'Total Accuracy vs Total Validation Accuracy')
Step 5: Implement the LRCN Approach
In this step, we will implement the LRCN Approach by combining Convolution and LSTM layers in a single model. Another similar approach can be to use a CNN model and LSTM model trained separately. The CNN model can be used to extract spatial features from the frames in the video, and for this purpose, a pre-trained model can be used, that can be fine-tuned for the problem. And the LSTM model can then use the features extracted by CNN, to predict the action being performed in the video.
But here, we will implement another approach known as the Long-term Recurrent Convolutional Network (LRCN), which combines CNN and LSTM layers in a single model. The Convolutional layers are used for spatial feature extraction from the frames, and the extracted spatial features are fed to LSTM layer(s) at each time-steps for temporal sequence modeling. This way the network learns spatiotemporal features directly in an end-to-end training, resulting in a robust model.
You can read the paper Long-term Recurrent Convolutional Networks for Visual Recognition and Description by Jeff Donahue (CVPR 2015), to learn more about this architecture. We will also use TimeDistributed wrapper layer, which allows applying the same layer to every frame of the video independently. So it makes a layer (around which it is wrapped) capable of taking input of shape (no_of_frames, width, height, num_of_channels) if originally the layer’s input shape was (width, height, num_of_channels) which is very beneficial as it allows to input the whole video into the model in a single shot.
Step 5.1: Construct the Model
To implement our LRCN architecture, we will use time-distributed Conv2D layers which will be followed by MaxPooling2D and Dropout layers. The feature extracted from the Conv2D layers will be then flattened using the Flatten layer and will be fed to a LSTM layer. The Dense layer with softmax activation will then use the output from the LSTM layer to predict the action being performed.
def create_LRCN_model():
'''
This function will construct the required LRCN model.
Returns:
model: It is the required constructed LRCN model.
'''
# We will use a Sequential model for model construction.
model = Sequential()
# Define the Model Architecture.
########################################################################################################################
model.add(TimeDistributed(Conv2D(16, (3, 3), padding='same',activation = 'relu'),
input_shape = (SEQUENCE_LENGTH, IMAGE_HEIGHT, IMAGE_WIDTH, 3)))
model.add(TimeDistributed(MaxPooling2D((4, 4))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(32, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((4, 4))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(64, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((2, 2))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(64, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((2, 2))))
#model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(32))
model.add(Dense(len(CLASSES_LIST), activation = 'softmax'))
########################################################################################################################
# Display the models summary.
model.summary()
# Return the constructed LRCN model.
return model
Now we will utilize the function create_LRCN_model() created above to construct the required LRCN model.
# Construct the required LRCN model.
LRCN_model = create_LRCN_model()
# Display the success message.
print("Model Created Successfully!")
Check Model’s Structure:
Now we will use the plot_model() function to check the structure of the constructed LRCN model. As we had checked for the previous model.
# Plot the structure of the contructed LRCN model.
plot_model(LRCN_model, to_file = 'LRCN_model_structure_plot.png', show_shapes = True, show_layer_names = True)
Step 5.2: Compile & Train the Model
After checking the structure, we will compile and start training the model.
# Create an Instance of Early Stopping Callback.
early_stopping_callback = EarlyStopping(monitor = 'val_loss', patience = 15, mode = 'min', restore_best_weights = True)
# Compile the model and specify loss function, optimizer and metrics to the model.
LRCN_model.compile(loss = 'categorical_crossentropy', optimizer = 'Adam', metrics = ["accuracy"])
# Start training the model.
LRCN_model_training_history = LRCN_model.fit(x = features_train, y = labels_train, epochs = 70, batch_size = 4 , shuffle = True, validation_split = 0.2, callbacks = [early_stopping_callback])
Evaluating the trained Model
As done for the previous one, we will evaluate the LRCN model on the test set.
# Evaluate the trained model.
model_evaluation_history = LRCN_model.evaluate(features_test, labels_test)
After that, we will save the model for future uses using the same technique we had used for the previous model.
# Get the loss and accuracy from model_evaluation_history.
model_evaluation_loss, model_evaluation_accuracy = model_evaluation_history
# Define the string date format.
# Get the current Date and Time in a DateTime Object.
# Convert the DateTime object to string according to the style mentioned in date_time_format string.
date_time_format = '%Y_%m_%d__%H_%M_%S'
current_date_time_dt = dt.datetime.now()
current_date_time_string = dt.datetime.strftime(current_date_time_dt, date_time_format)
# Define a useful name for our model to make it easy for us while navigating through multiple saved models.
model_file_name = f'LRCN_model___Date_Time_{current_date_time_string}___Loss_{model_evaluation_loss}___Accuracy_{model_evaluation_accuracy}.h5'
# Save the Model.
LRCN_model.save(model_file_name)
Step 5.3: Plot Model’s Loss & Accuracy Curves
Now we will utilize the function plot_metric() we had created above to visualize the training and validation metrics of this model.
# Visualize the training and validation loss metrices.
plot_metric(LRCN_model_training_history, 'loss', 'val_loss', 'Total Loss vs Total Validation Loss')
# Visualize the training and validation accuracy metrices.
plot_metric(LRCN_model_training_history, 'accuracy', 'val_accuracy', 'Total Accuracy vs Total Validation Accuracy')
Step 6: Test the Best Performing Model on YouTube videos
From the results, it seems that the LRCN model performed significantly well for a small number of classes. so in this step, we will put the LRCN model to test on some youtube videos.
Create a Function to Download YouTube Videos:
We will create a function download_youtube_videos() to download the YouTube videos first using pafy library. The library only requires a URL to a video to download it along with its associated metadata like the title of the video.
def download_youtube_videos(youtube_video_url, output_directory):
'''
This function downloads the youtube video whose URL is passed to it as an argument.
Args:
youtube_video_url: URL of the video that is required to be downloaded.
output_directory: The directory path to which the video needs to be stored after downloading.
Returns:
title: The title of the downloaded youtube video.
'''
# Create a video object which contains useful information about the video.
video = pafy.new(youtube_video_url)
# Retrieve the title of the video.
title = video.title
# Get the best available quality object for the video.
video_best = video.getbest()
# Construct the output file path.
output_file_path = f'{output_directory}/{title}.mp4'
# Download the youtube video at the best available quality and store it to the contructed path.
video_best.download(filepath = output_file_path, quiet = True)
# Return the video title.
return title
Download a Test Video:
Now we will utilize the function download_youtube_videos() created above to download a youtube video on which the LRCN model will be tested.
# Make the Output directory if it does not exist
test_videos_directory = 'test_videos'
os.makedirs(test_videos_directory, exist_ok = True)
# Download a YouTube Video.
video_title = download_youtube_videos('https://www.youtube.com/watch?v=8u0qjmHIOcE', test_videos_directory)
# Get the YouTube Video's path we just downloaded.
input_video_file_path = f'{test_videos_directory}/{video_title}.mp4'
Create a Function To Perform Action Recognition on Videos
Next, we will create a function predict_on_video() that will simply read a video frame by frame from the path passed in as an argument and will perform action recognition on video and save the results.
def predict_on_video(video_file_path, output_file_path, SEQUENCE_LENGTH):
'''
This function will perform action recognition on a video using the LRCN model.
Args:
video_file_path: The path of the video stored in the disk on which the action recognition is to be performed.
output_file_path: The path where the ouput video with the predicted action being performed overlayed will be stored.
SEQUENCE_LENGTH: The fixed number of frames of a video that can be passed to the model as one sequence.
'''
# Initialize the VideoCapture object to read from the video file.
video_reader = cv2.VideoCapture(video_file_path)
# Get the width and height of the video.
original_video_width = int(video_reader.get(cv2.CAP_PROP_FRAME_WIDTH))
original_video_height = int(video_reader.get(cv2.CAP_PROP_FRAME_HEIGHT))
# Initialize the VideoWriter Object to store the output video in the disk.
video_writer = cv2.VideoWriter(output_file_path, cv2.VideoWriter_fourcc('M', 'P', '4', 'V'),
video_reader.get(cv2.CAP_PROP_FPS), (original_video_width, original_video_height))
# Declare a queue to store video frames.
frames_queue = deque(maxlen = SEQUENCE_LENGTH)
# Initialize a variable to store the predicted action being performed in the video.
predicted_class_name = ''
# Iterate until the video is accessed successfully.
while video_reader.isOpened():
# Read the frame.
ok, frame = video_reader.read()
# Check if frame is not read properly then break the loop.
if not ok:
break
# Resize the Frame to fixed Dimensions.
resized_frame = cv2.resize(frame, (IMAGE_HEIGHT, IMAGE_WIDTH))
# Normalize the resized frame by dividing it with 255 so that each pixel value then lies between 0 and 1.
normalized_frame = resized_frame / 255
# Appending the pre-processed frame into the frames list.
frames_queue.append(normalized_frame)
# Check if the number of frames in the queue are equal to the fixed sequence length.
if len(frames_queue) == SEQUENCE_LENGTH:
# Pass the normalized frames to the model and get the predicted probabilities.
predicted_labels_probabilities = LRCN_model.predict(np.expand_dims(frames_queue, axis = 0))[0]
# Get the index of class with highest probability.
predicted_label = np.argmax(predicted_labels_probabilities)
# Get the class name using the retrieved index.
predicted_class_name = CLASSES_LIST[predicted_label]
# Write predicted class name on top of the frame.
cv2.putText(frame, predicted_class_name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# Write The frame into the disk using the VideoWriter Object.
video_writer.write(frame)
# Release the VideoCapture and VideoWriter objects.
video_reader.release()
video_writer.release()
Perform Action Recognition on the Test Video
Now we will utilize the function predict_on_video() created above to perform action recognition on the test video we had downloaded using the function download_youtube_videos() and display the output video with the predicted action overlayed on it.
# Construct the output video path.
output_video_file_path = f'{test_videos_directory}/{video_title}-Output-SeqLen{SEQUENCE_LENGTH}.mp4'
# Perform Action Recognition on the Test Video.
predict_on_video(input_video_file_path, output_video_file_path, SEQUENCE_LENGTH)
# Display the output video.
VideoFileClip(output_video_file_path, audio=False, target_resolution=(300,None)).ipython_display()
Create a Function To Perform a Single Prediction on Videos
Now let’s create a function that will perform a single prediction for the complete videos. We will extract evenly distributed N(SEQUENCE_LENGTH) frames from the entire video and pass them to the LRCN model. This approach is really useful when you are working with videos containing only one activity as it saves unnecessary computations and time in that scenario.
def predict_single_action(video_file_path, SEQUENCE_LENGTH):
'''
This function will perform single action recognition prediction on a video using the LRCN model.
Args:
video_file_path: The path of the video stored in the disk on which the action recognition is to be performed.
SEQUENCE_LENGTH: The fixed number of frames of a video that can be passed to the model as one sequence.
'''
# Initialize the VideoCapture object to read from the video file.
video_reader = cv2.VideoCapture(video_file_path)
# Get the width and height of the video.
original_video_width = int(video_reader.get(cv2.CAP_PROP_FRAME_WIDTH))
original_video_height = int(video_reader.get(cv2.CAP_PROP_FRAME_HEIGHT))
# Declare a list to store video frames we will extract.
frames_list = []
# Initialize a variable to store the predicted action being performed in the video.
predicted_class_name = ''
# Get the number of frames in the video.
video_frames_count = int(video_reader.get(cv2.CAP_PROP_FRAME_COUNT))
# Calculate the interval after which frames will be added to the list.
skip_frames_window = max(int(video_frames_count/SEQUENCE_LENGTH),1)
# Iterating the number of times equal to the fixed length of sequence.
for frame_counter in range(SEQUENCE_LENGTH):
# Set the current frame position of the video.
video_reader.set(cv2.CAP_PROP_POS_FRAMES, frame_counter * skip_frames_window)
# Read a frame.
success, frame = video_reader.read()
# Check if frame is not read properly then break the loop.
if not success:
break
# Resize the Frame to fixed Dimensions.
resized_frame = cv2.resize(frame, (IMAGE_HEIGHT, IMAGE_WIDTH))
# Normalize the resized frame by dividing it with 255 so that each pixel value then lies between 0 and 1.
normalized_frame = resized_frame / 255
# Appending the pre-processed frame into the frames list
frames_list.append(normalized_frame)
# Passing the pre-processed frames to the model and get the predicted probabilities.
predicted_labels_probabilities = LRCN_model.predict(np.expand_dims(frames_list, axis = 0))[0]
# Get the index of class with highest probability.
predicted_label = np.argmax(predicted_labels_probabilities)
# Get the class name using the retrieved index.
predicted_class_name = CLASSES_LIST[predicted_label]
# Display the predicted action along with the prediction confidence.
print(f'Action Predicted: {predicted_class_name}\nConfidence: {predicted_labels_probabilities[predicted_label]}')
# Release the VideoCapture object.
video_reader.release()
Perform Single Prediction on a Test Video
Now we will utilize the function predict_single_action() created above to perform a single prediction on a complete youtube test video that we will download using the function download_youtube_videos(), we had created above.
# Download the youtube video.
video_title = download_youtube_videos('https://youtu.be/fc3w827kwyA', test_videos_directory)
# Construct tihe nput youtube video path
input_video_file_path = f'{test_videos_directory}/{video_title}.mp4'
# Perform Single Prediction on the Test Video.
predict_single_action(input_video_file_path, SEQUENCE_LENGTH)
# Display the input video.
VideoFileClip(input_video_file_path, audio=False, target_resolution=(300,None)).ipython_display()
Action Predicted: TaiChi
Confidence: 0.94
Join My Course Computer Vision For Building Cutting Edge Applications Course
The only course out there that goes beyond basic AI Applications and teaches you how to create next-level apps that utilize physics, deep learning, classical image processing, hand and body gestures. Don’t miss your chance to level up and take your career to new heights
You’ll Learn about:
Creating GUI interfaces for python AI scripts.
Creating .exe DL applications
Using a Physics library in Python & integrating it with AI
Advance Image Processing Skills
Advance Gesture Recognition with Mediapipe
Task Automation with AI & CV
Training an SVM machine Learning Model.
Creating & Cleaning an ML dataset from scratch.
Training DL models & how to use CNN’s & LSTMS.
Creating 10 Advance AI/CV Applications
& More
Whether you’re a seasoned AI professional or someone just looking to start out in AI, this is the course that will teach you, how to Architect & Build complex, real world and thrilling AI applications
In this tutorial, we discussed a number of approaches to perform video classification and learned about the importance of the temporal aspect of data to gain higher accuracy in video classification and implemented two CNN + LSTM architectures in TensorFlow to perform Human Action Recognition on videos by utilizing the temporal as well as spatial information of the data.
We also learned to perform pre-processing on videos using the OpenCV library to create an image dataset, we also looked into getting youtube videos using just their URLs with the help of the Pafy library for testing our model.
Now let’s discuss a limitation in our application that you should know about, our action recognizer cannot work on multiple people performing different activities. There should be only one person in the frame to correctly recognize the activity of that person by our action recognizer, this is because the data was in this manner, on which we had trained our model.
You can use some different dataset that has been annotated for more than one person’s activity and also provides the bounding box coordinates of the person along with the activity he is performing, to overcome this limitation.
Or a hacky way is to crop out each person and perform activity recognition separately on each person but this will be computationally very expensive.
That is all for this lesson, if you enjoyed this tutorial, let me know in the comments, you can also reach out to me personally for a 1 on 1 Coaching/consultation session in AI/computer vision regarding your project or your career.
Hire Us
Let our team of expert engineers and managers build your next big project using Bleeding Edge AI Tools & Technologies

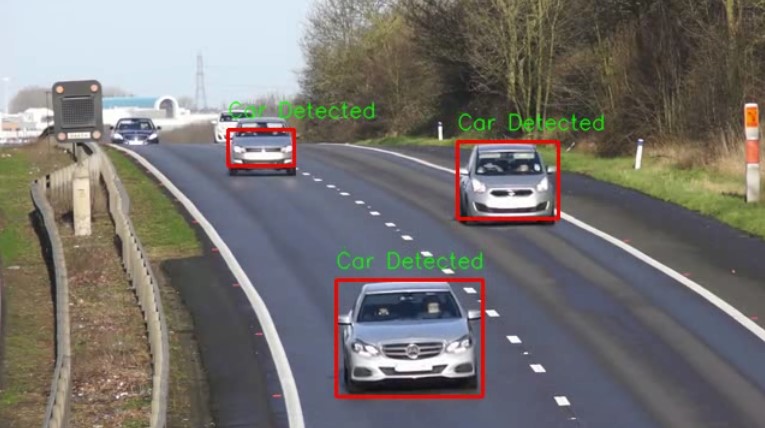








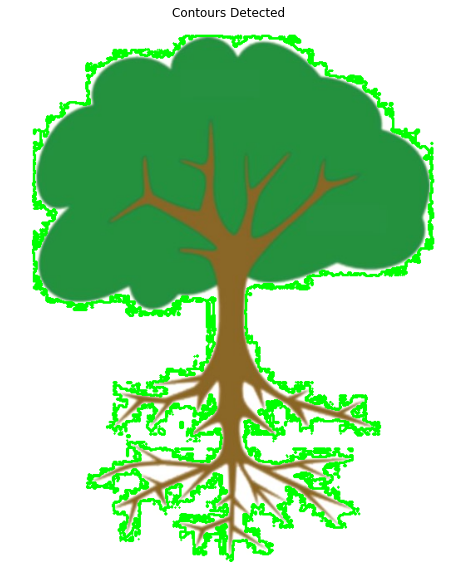

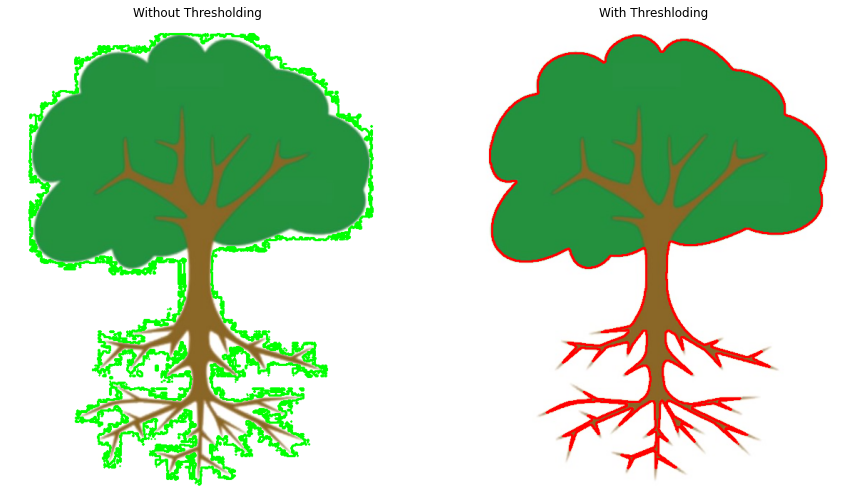





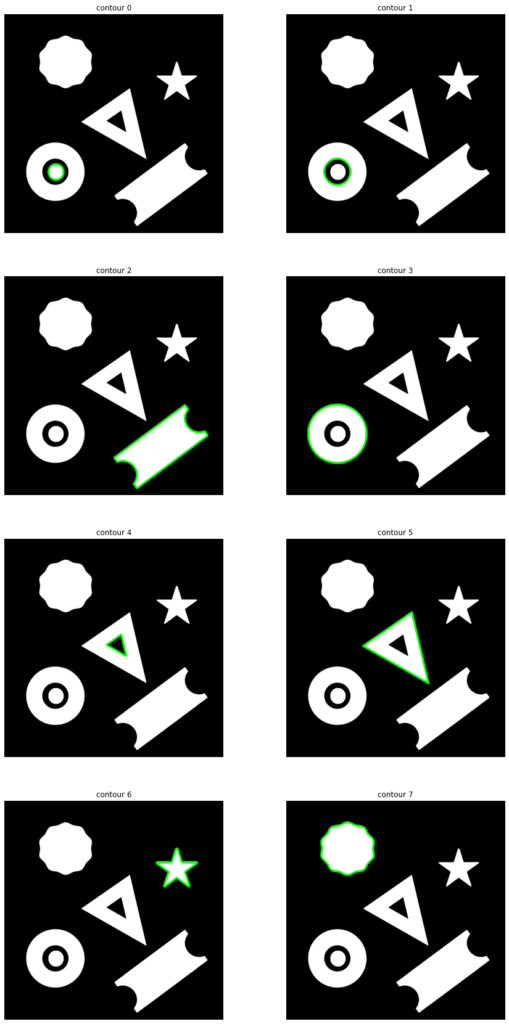
























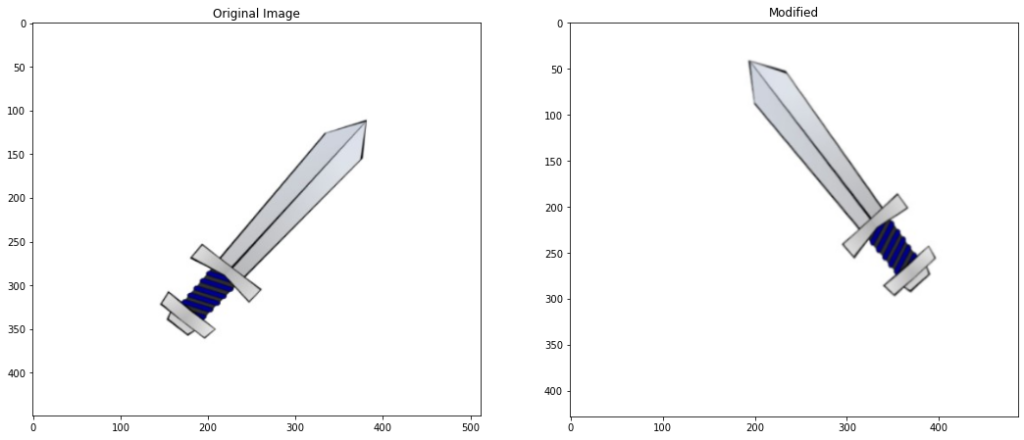
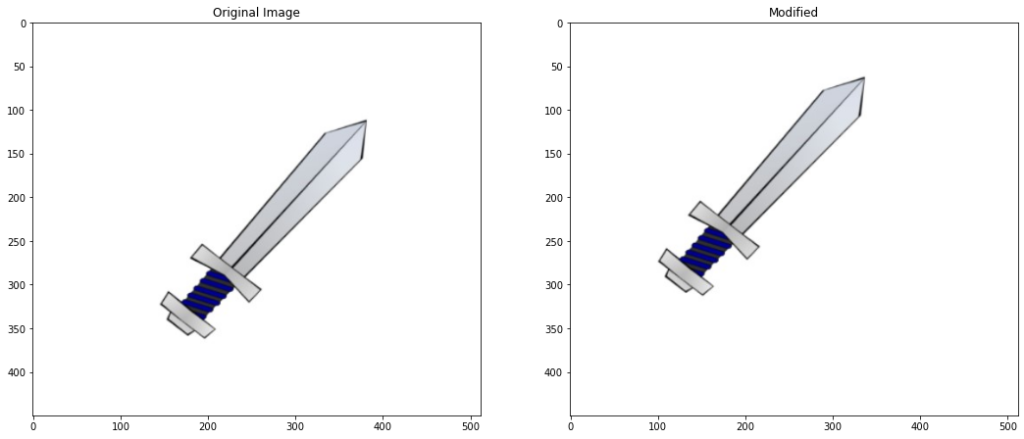
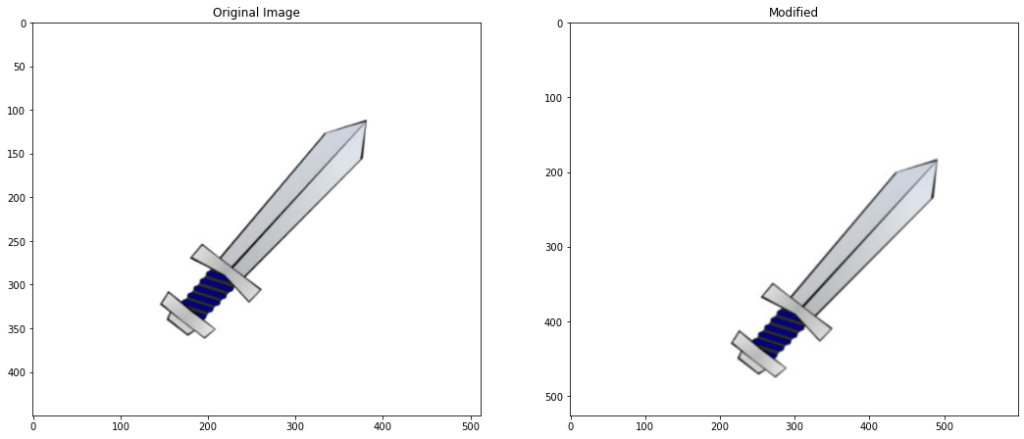
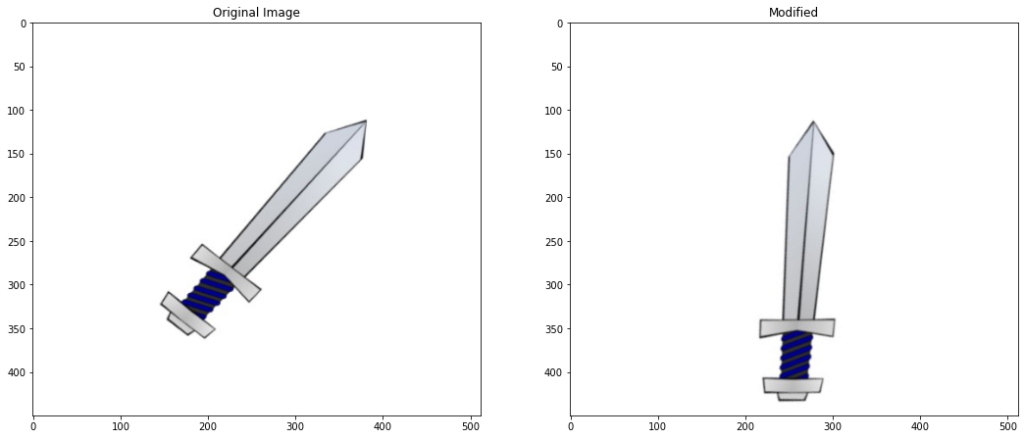
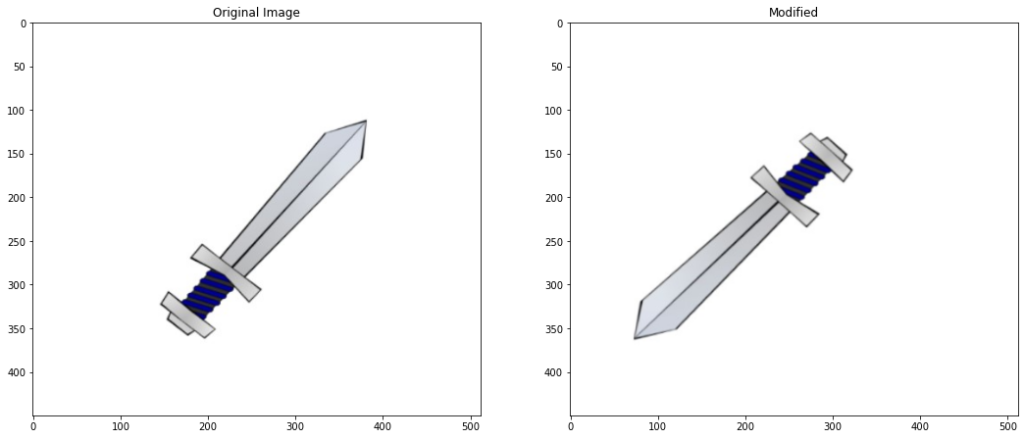
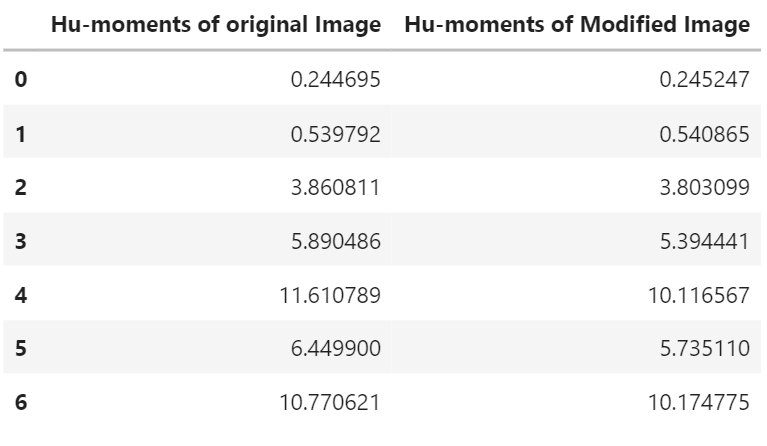







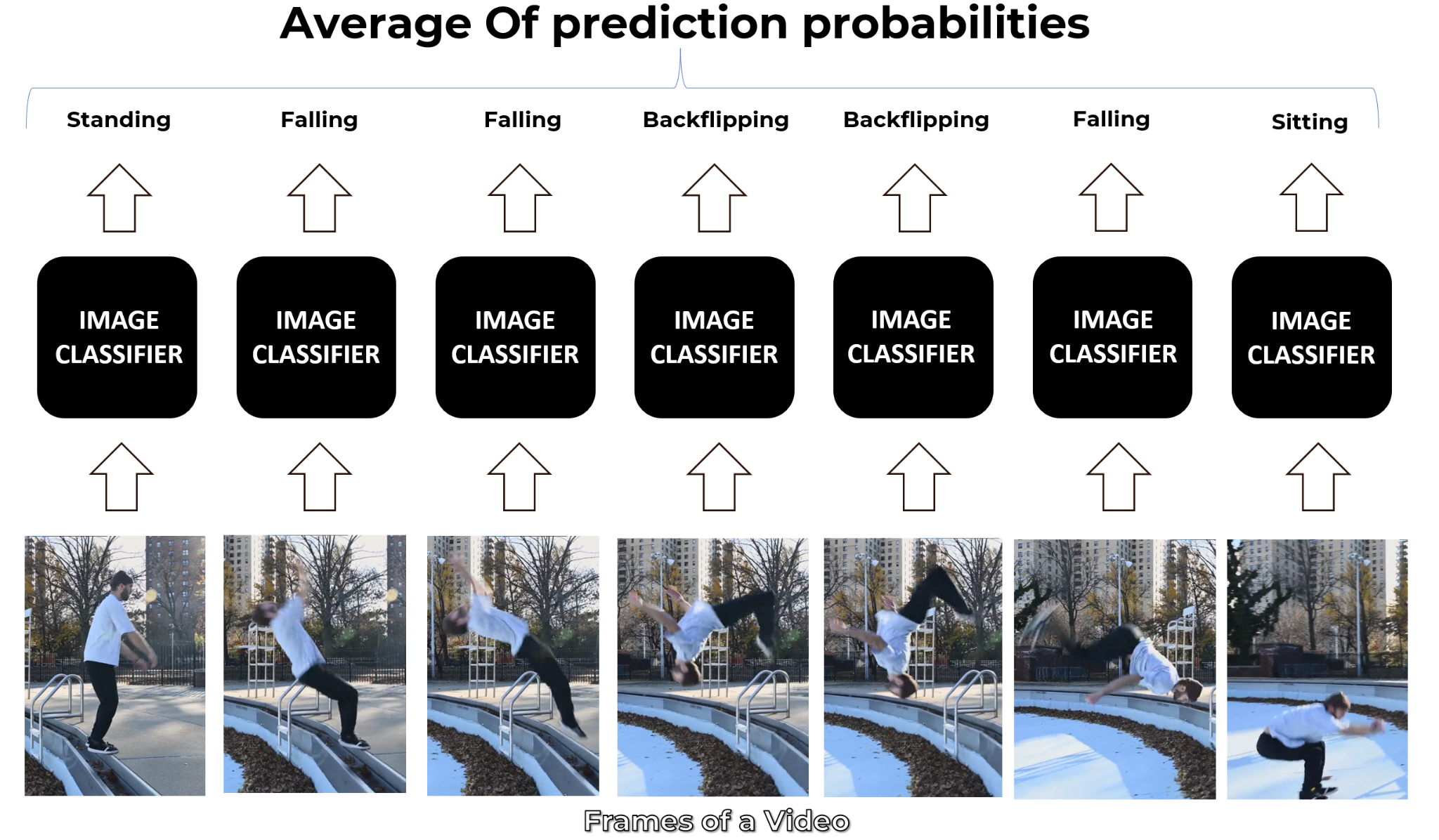





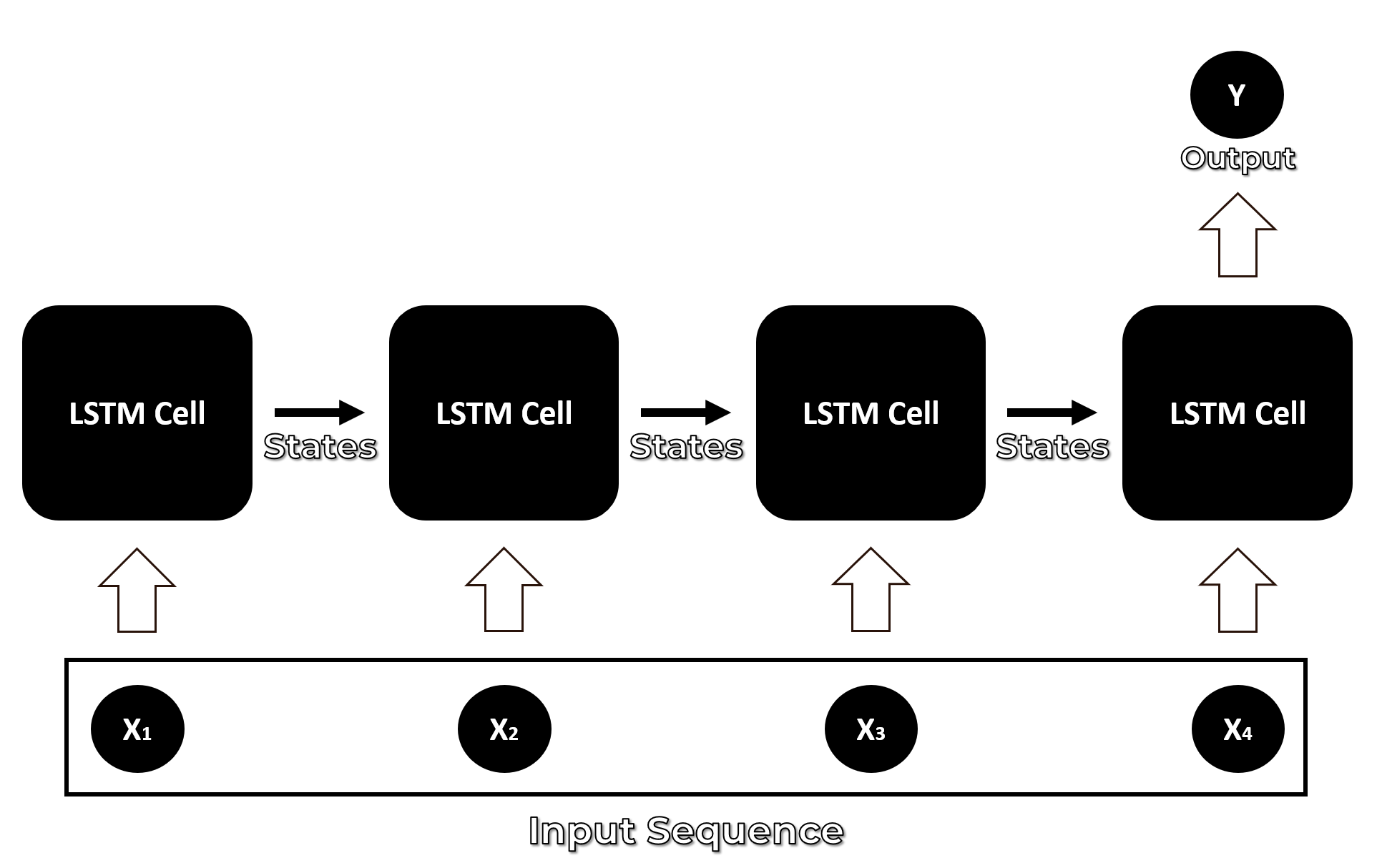


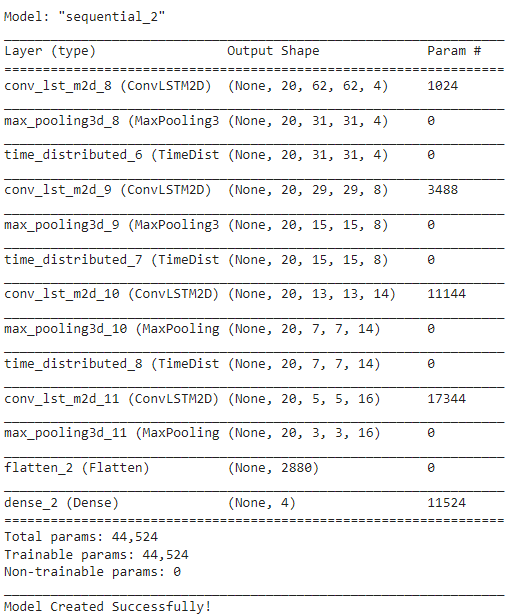
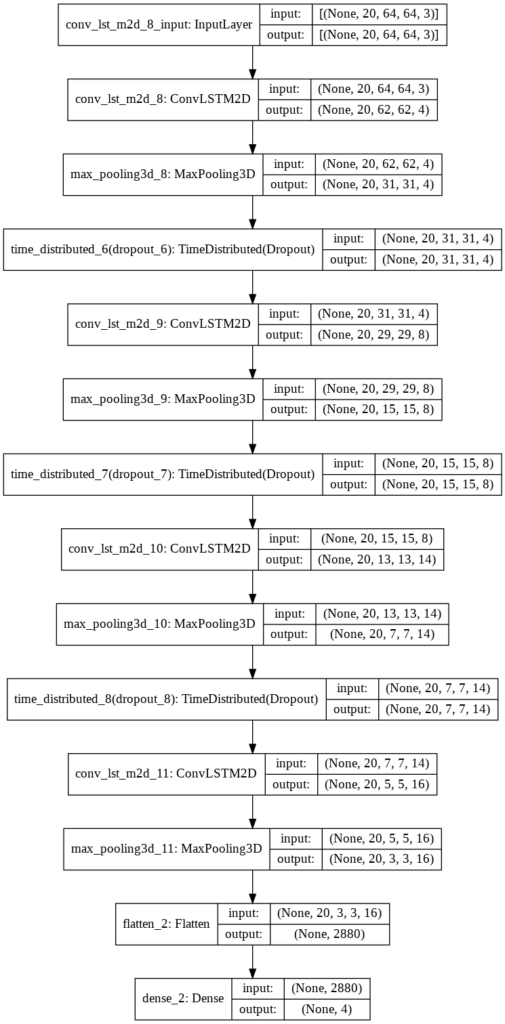
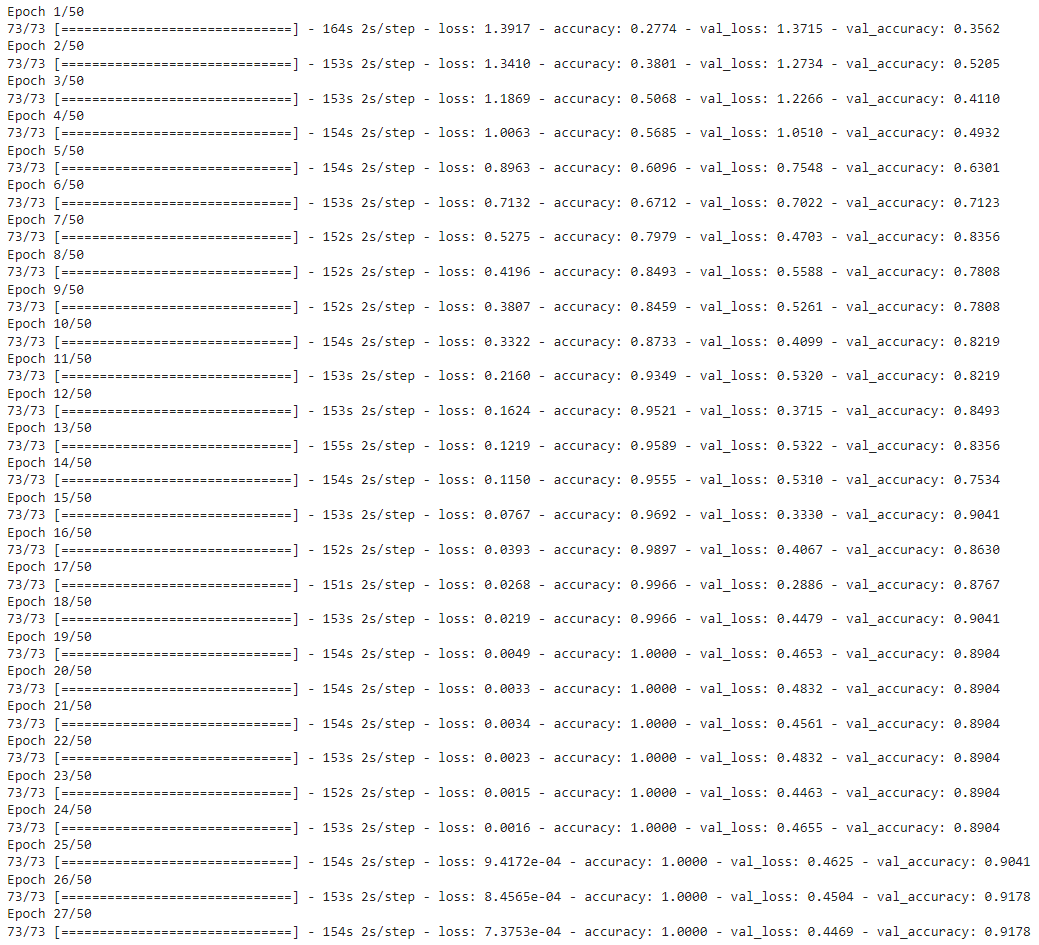
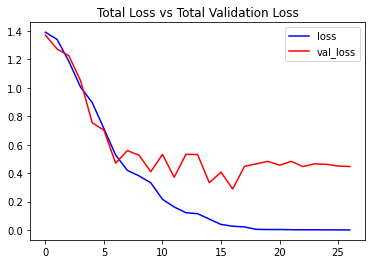
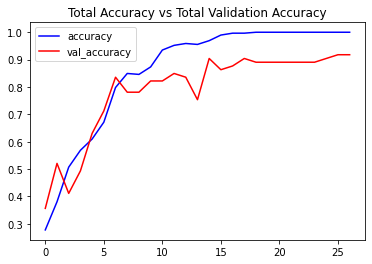

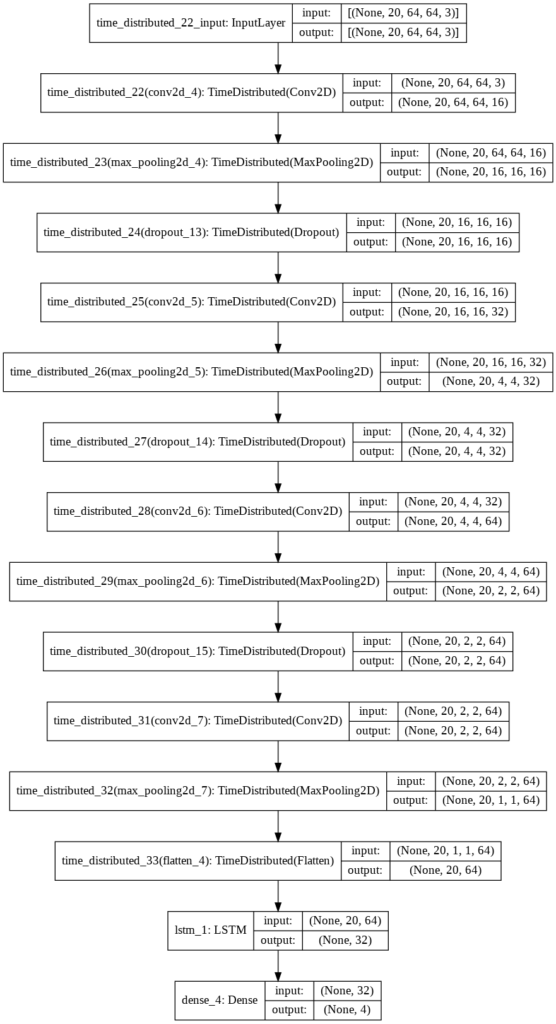
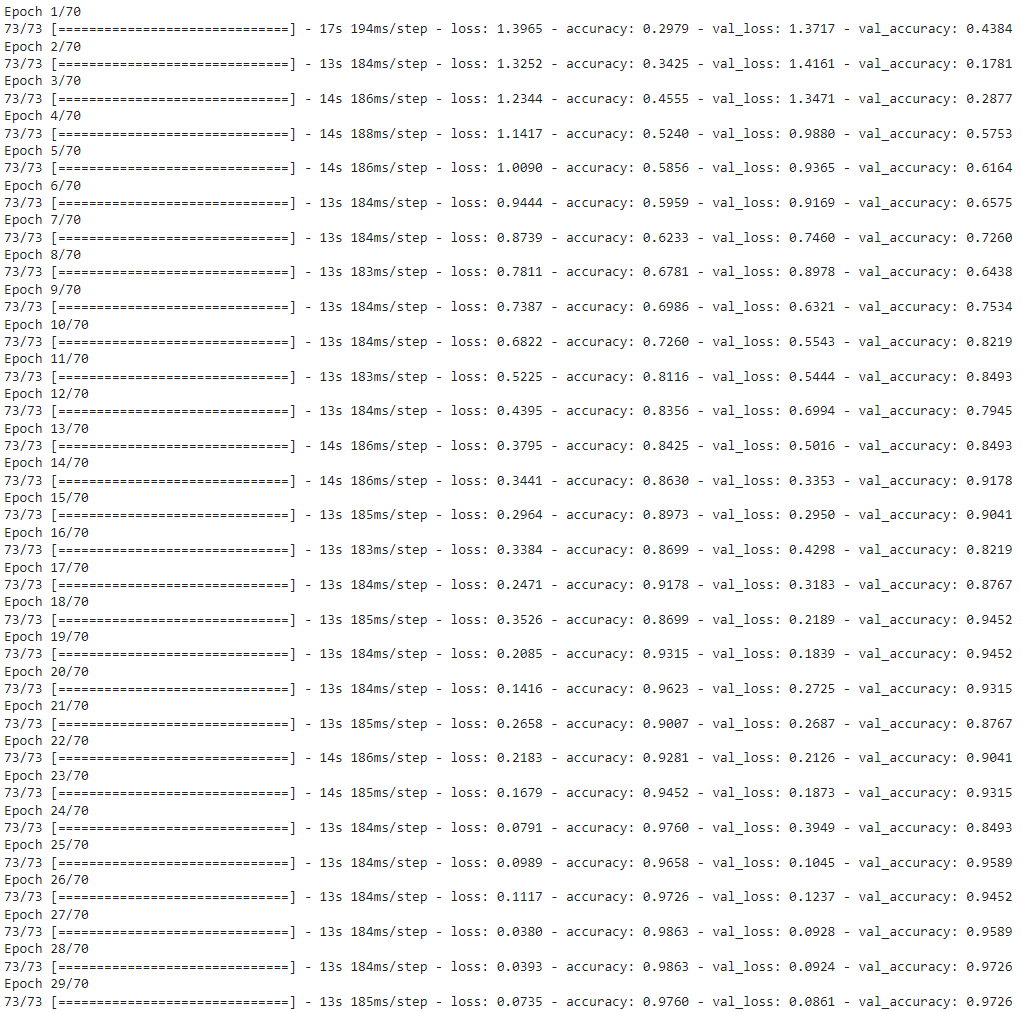

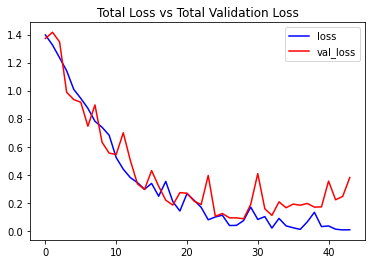
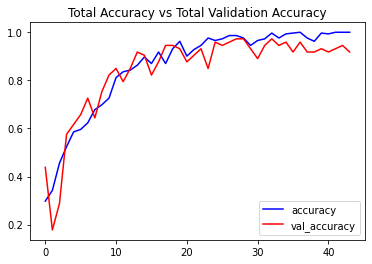

{kind=link}