Watch Video Here
In the previous episode of the Computer Vision For Everyone (CVFE) course, we had discussed the history of AI in detail, covering almost all major events so far from 1950 along with the winters AI faced and their causes. And I had also explained what exactly the terms AI, Machine Learning and Deep Learning mean, in the simplest manner possible.
Now today in this episode, we’ll go a little deeper into machine learning and take a look at different branches of machine learning in detail with their examples.
This is the 3rd part of our 4-parts series on AI. I have witnessed many experienced practitioners that have been working in the field for years but do not know the basic fundamentals of AI which is quite surprising as a solid foundation in the theoretical concepts of AI/ML plays a major role in working with AI/ML algorithms efficiently.
So through this series of tutorials, I’m trying to provide a thorough understanding of the Artificial Intelligence field for everyone, with an increase in technicality and depth on each subsequent tutorial.
Alright, so without further ado, let’s get started.
Machine Learning can be further divided into three different branches i.e., Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Other than these three, there are also some hybrid branches too but we’ll learn about them in the next episode.
For now let’s look at each of these three core ML branches, one by one.
- Supervised Learning.
- Unsupervised Learning.
- Reinforcement Learning.
Supervised Learning
Supervised Learning is the most common branch of machine learning, in fact, most of the applications you see these days are examples of supervised learning.
For example, a House Price Prediction System is a popular supervised machine learning problem, where a Machine Learning model predicts the price of a house by looking at some features of the house like house area, the number of bedrooms it has and its location, etc.

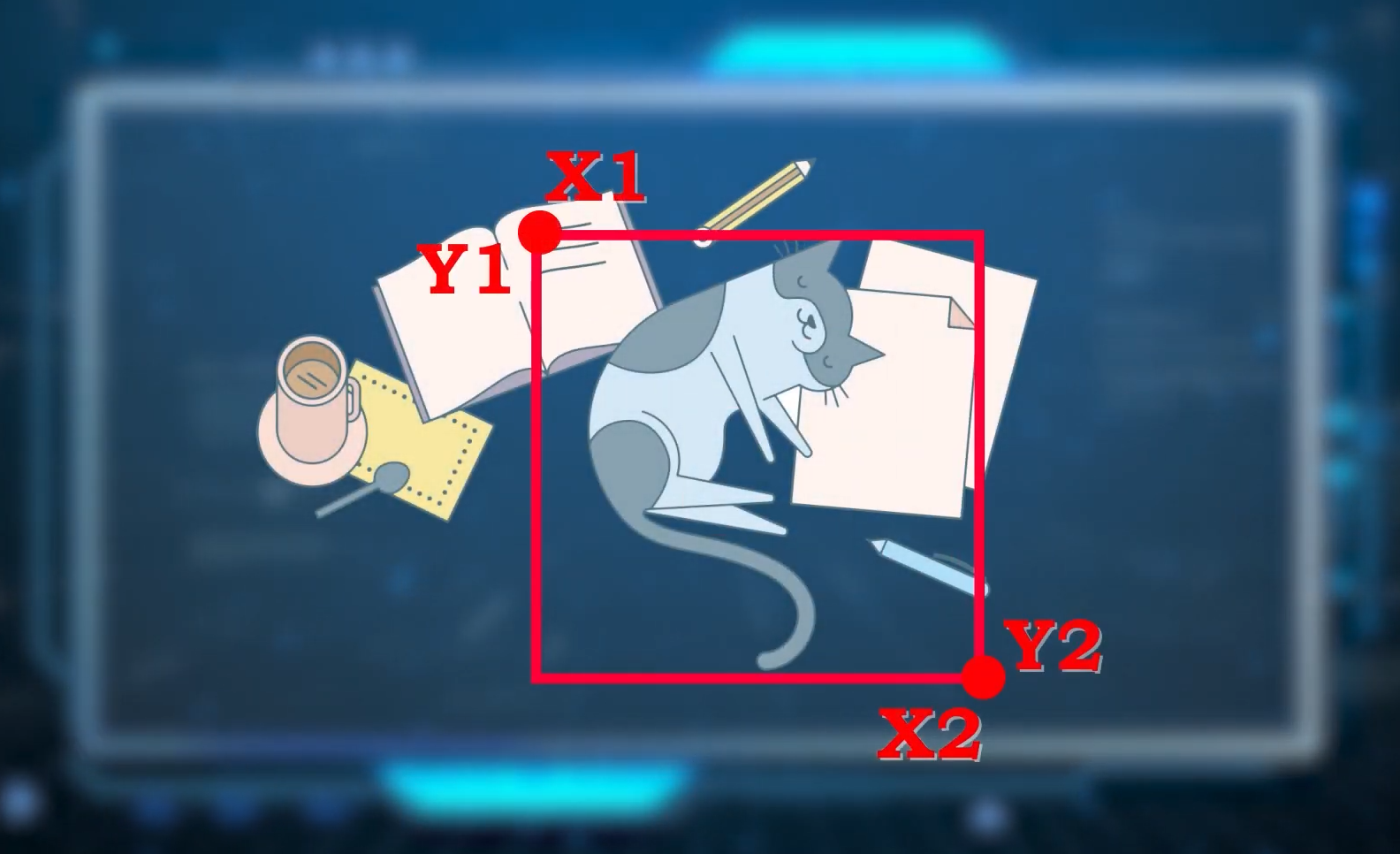
Also, it is worth noting that when a Machine Learning model predicts a number, then it’s also called a Regression Problem and it has many types. For example, localizing an object in images/videos using an object detector is also a regression problem, as in this scenario the output i.e., the coordinates (x1, y1, x2, and y2) of a bounding box enclosing the object are numbers.
Another example for Supervised Learning would be a machine learning model looking at an image or a video and predicting a category/label of the object in it.

And whenever a machine learning model predicts a class label that is normally based on some features of the object in the image/video, the process is called a Classification Task or Problem. So both Classification & Regression fall in supervised learning.
But what exactly is this Supervised Learning? We have looked at its examples but how do we define this? Well, it’s pretty simple;
In Supervised Learning, you first have to label all the training examples. Like, suppose if you’re doing something like a Cat & Dog Classification, you’ll first label all training images or videos with either cat or dog. Then you feed all the training examples to the machine learning model, and the model then trains or learns from these examples.

And after it has been trained, we can then show the model some test images or videos that it hasn’t seen before to get the predictions on the test examples and evaluate the model’s performance by verifying the results.

This Whole process is called Supervised Machine Learning. Now let’s check its definition in technical terms.
In Supervised Learning, we take feature (x), which can be anything from pixel values to extracted house features, and map them to an output (y) which can be anything from labels like cat/dog to a regression number like house prices.
And this X and Y is an input-output pair and with an increase in the training examples, these input-output pairs also increase, and the machine learning model (whose job is to learn this input-output pair relationship during the training process) will be more accurate.
So essentially when we train a model, ideally it learns a function, capable of mapping any unseen input example to an appropriate output. And this is supervised learning, although supervised learning is responsible for most of the AI applications we see today. But the biggest issue with this approach is that it takes a lot of time and human effort to create the required input-output pairs for training the model.
So for example, if you had 10,000 images of cats and dogs then you’ll first have to go and label each with either a cat or a dog label, which is a very time-consuming and tedious process.
Unsupervised Learning
Let’s take a look at another machine learning approach called Unsupervised Learning where you don’t have to label anything.
So you have an input (x) but don’t have to map it to output (y), the goal of the machine learning model here is to learn the internal structures, distributions, or patterns in the data.
But how is this useful? Well, let’s discuss Clustering to find out, which is a type of unsupervised learning problem.
Suppose you have lots of unlabeled images of 3 simple shapes like circles, rectangles, and triangles, and all these images are mixed up. So what you can do is show all these examples to an unsupervised machine learning model.

The model will learn the common patterns and will group them based on similarity like for e.g if just one feature or pattern i.e., the number of corners is considered then the model will cluster the images into 3 different groups i.e., of course, Circle, Triangle, and Rectangle.
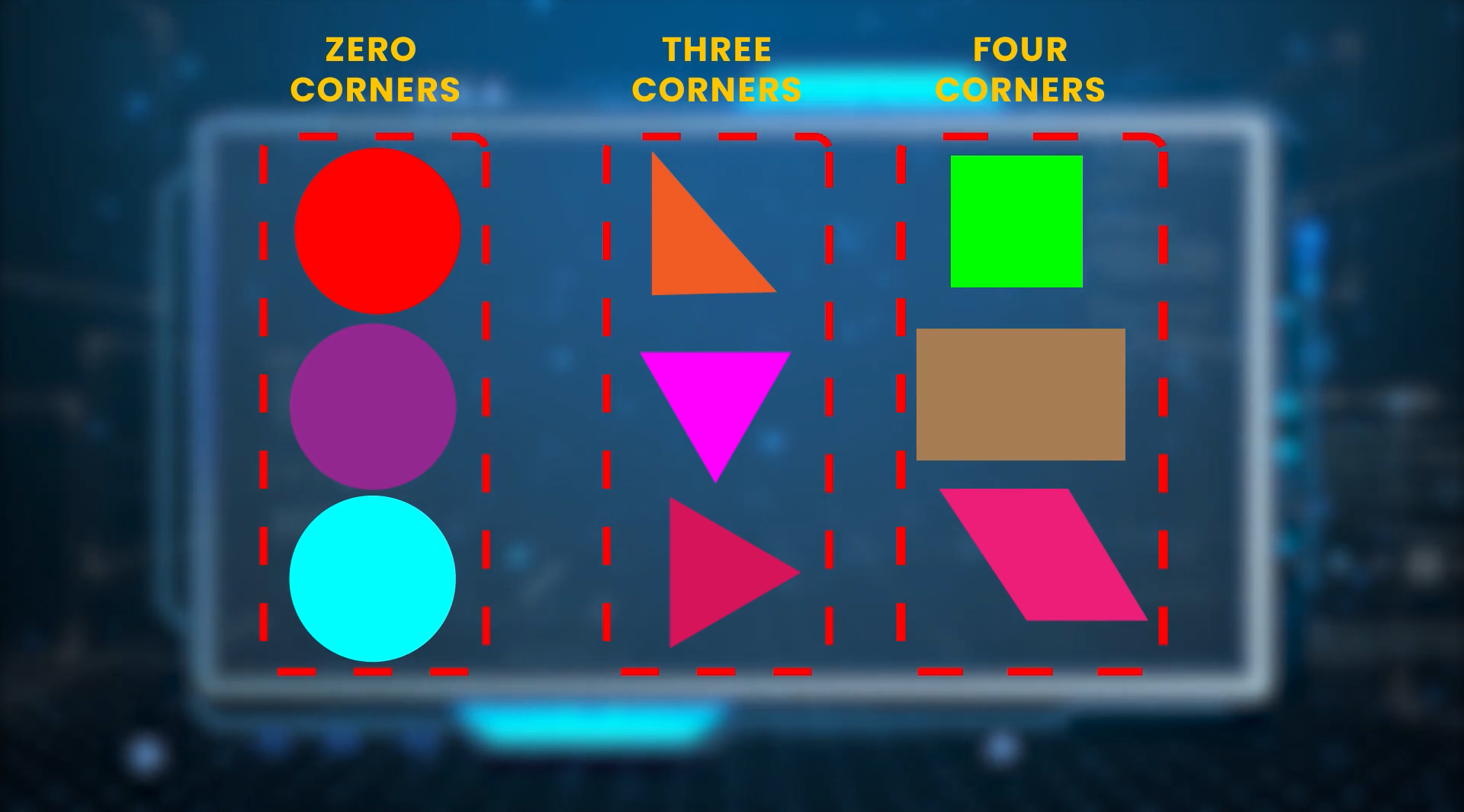
And Immediately you’ll recognize the actual class and label these three clusters and this will save the effort of labeling each image separately but this is a very basic example and it isn’t always this simple. Suppose if instead of shapes you had 3 classes of animals like cats, dogs, and reptiles.

Then ideally the clustering algorithm should give you 3 clusters of images with each cluster having images of only one class but this doesn’t happen in reality because clustering just based on raw pixels is not meaningful, the algorithm may cluster images with similar backgrounds or some other thing.

So what we can do here is extract some meaningful features and then cluster data based on those features. And in the end, you can use some metrics to determine if the clusters generated by the algorithm are meaningful or not.
Clustering is popularly used in the e-commerce Industry to cluster customers into different segments like frequent buyers, or people who purchase during Sales, etc.
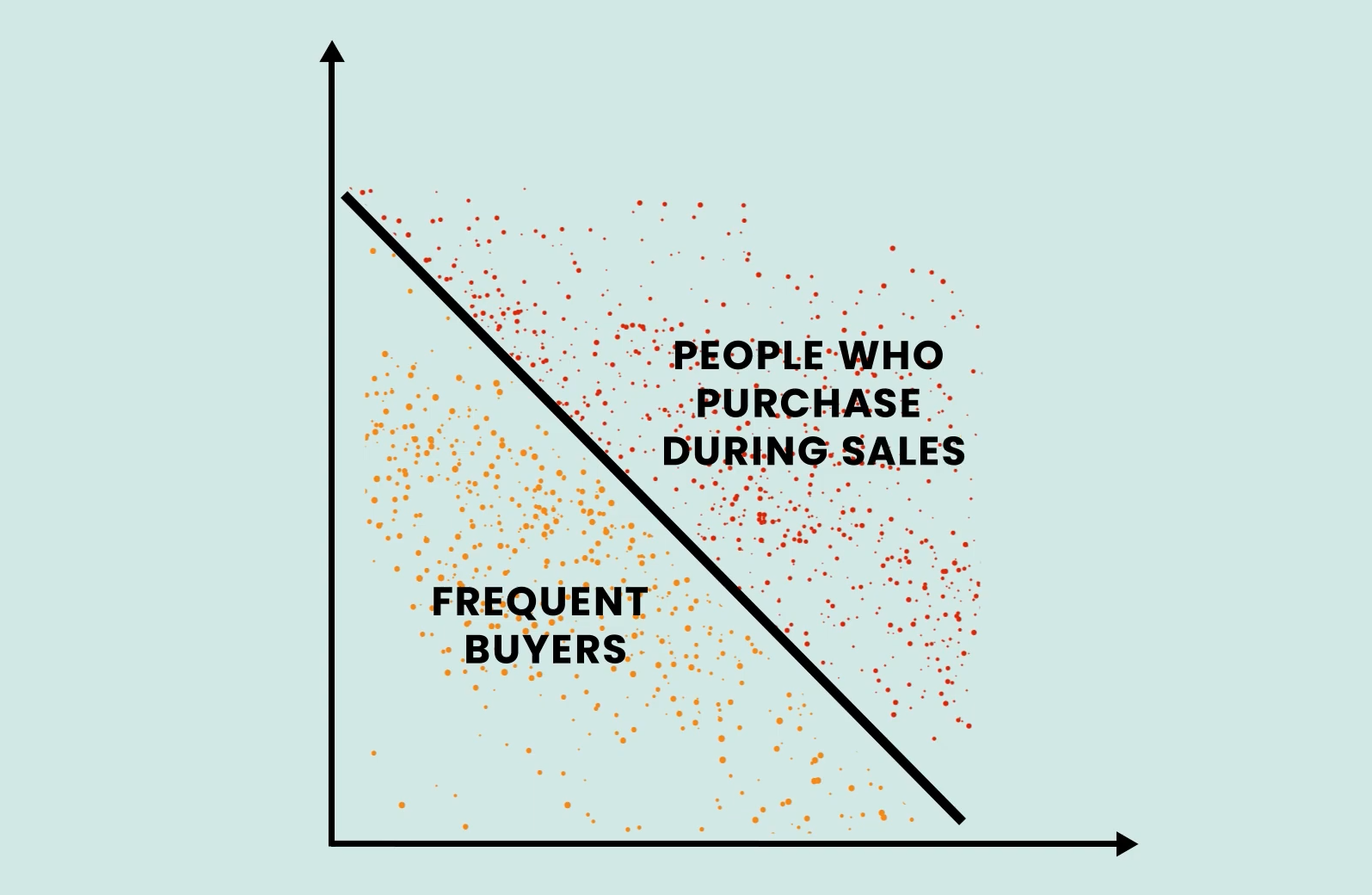
This helps a lot in designing customized marketing campaigns. Another type of Unsupervised problem is called Association.
In this technique, we analyze data and discover rules that describe groups of data, for example, we can find patterns like if a certain data group contains Feature A, then there is a high probability it will contain Feature B too.

So Association models help in associating one variable with a data group. Let’s check an example. If we train an association algorithm on customer purchases then it may tell us things like, Customers who bought Item ‘A’ also bought item “B and C”. So if a buyer buys a fan, he may see some excellent recommendations like a rope xD.
[Insert cliparts of fan and rope]
So when you see recommendations in online stores while shopping, it happens due to association algorithms running in the background on your data.
Reinforcement Learning
Alright, we have looked at Supervised Learning & Unsupervised Learning. Now let’s talk about Reinforcement Learning which is something totally different.
Now before we get into Reinforcement Learning, I first want to discuss the necessity for it. So consider, if you wanted to train an AI to walk then what you could do is attach a ton of sensors to someone’s legs, and capture things like angular velocity, acceleration, muscle tension, and whatnot. Then feed all these data points to a supervised algorithm and try to train it so it learns to walk.

But here’s the thing, this approach will not prove to be much effective because it’s really hard to describe how to walk or what particular features to capture or study in order to learn to walk.
So a much better approach would be learning to walk by trial and error and this is what Reinforcement Learning is. It is used whenever we’re faced with a problem that is hard to describe. Google’s Deepmind got some really interesting results when they trained AI to walk using reinforcement learning.

In Reinforcement learning, you have an agent, which has to interact with some given environment in order to reach its goal.
Consider the example of a self-driving car, where the agent is the car and the environment can be the roads, people, or any obstacles that the car has to deal with. The objective of this agent i.e., a car is to reach its goal or destination while avoiding any obstacles in the way.

Now what happens during the training phase is that the agent tries to reach the goal by taking actions, these actions are like moving the car forward, backward, taking turns, slowing down, etc.

And the environment has a state that changes as cars can move towards the agent, an obstacle might block the agent, or anything can happen in the environment.

As the agent gets closer and closer to the goal, it gets rewarded, this way the agent knows that the actions it took were correct as it was rewarded.

And similarly, if the agent makes mistakes it’s punished with a penalty and this tells the agent that the actions it took were bad.

This whole process is repeated in a loop over and over during the training until the agent learns to avoid mistakes and reach the goal using an effective approach.
Also when it comes to AI playing games, reinforcement learning is the go-to approach. In fact, OpenAI’s popular 2016 victory against the World Go champion was built on Deep Reinforcement Learning.
Summary
In this episode of CVFE, we learned about the three primary Paradigms in machine learning i.e., Supervised Learning, Unsupervised Learning, and Reinforcement Learning in-depth with examples.
Now you have learned the pros and cons of all three and the approach that you should use totally depends on the problem that you are trying to solve. If you are still confused about the approach best suited for your project you can ask me in the comments section.
You can reach out to me personally for a 1 on 1 consultation session in AI/computer vision regarding your project. Our talented team of vision engineers will help you every step of the way. Get on a call with me directly here.
Ready to seriously dive into State of the Art AI & Computer Vision?
Then Sign up for these premium Courses by Bleed AI
With this I conclude this episode, in the next and final part of this series, I’ll go deeper and discuss the hybrid fields of AI, applied fields, AI industries, AI applications and finally we’ll connect everything we have discussed together and show you how everything relates with each other.
Share the post with your colleagues if you have found it useful. Also, make sure to check out part 1 and part 2 of the series and Subscribe to the Bleed AI YouTube channel to be notified when new videos are released.
[optin-monster slug=”urzgphotn9bfjtqiydj2″]






Good work