Watch Video Here
In the previous episode of the Computer Vision For Everyone (CVFE) course, we discussed different branches of machine learning in detail with examples. Now in today’s episode, we’ll further dive in, by learning about some interesting hybrid branches of AI.

We’ll also learn about AI industries, AI applications, applied AI fields, and a lot more, including how everything is connected with each other. Believe me, this is one tutorial that will tie a lot of AI Concepts together that you’ve heard out there, you don’t want to skip it.
By the way, this is the final part of Artificial Intelligence 4 levels of explanation. All the four posts are titled as:
- Artificial Intelligence: 4 Levels of Explanation Part 1 (Episode 3 | CVFE)
- History of AI, Ritakse Of Machine Learning and Deep Learning | Artificial Intelligence Part 2/4 (Episode 4 | CVFE)
- Different Branches of Machine Learning | Artificial Intelligence Part 3/4 (Episode 5 | CVFE)
- Hybrid Branches of AI with Complete Overview of the Field | Artificial Intelligence Part 4/4 (Episode 6 | CVFE) (Current tutorial)
This tutorial is built on top of the previous ones so make sure to go over those parts first if you haven’t already, especially the last one in which I had covered the core branches of machine learning. If you already know about a high-level overview of supervised, unsupervised, and reinforcement learning then you’re all good.
Alright, so without further ado, let’s get into it.
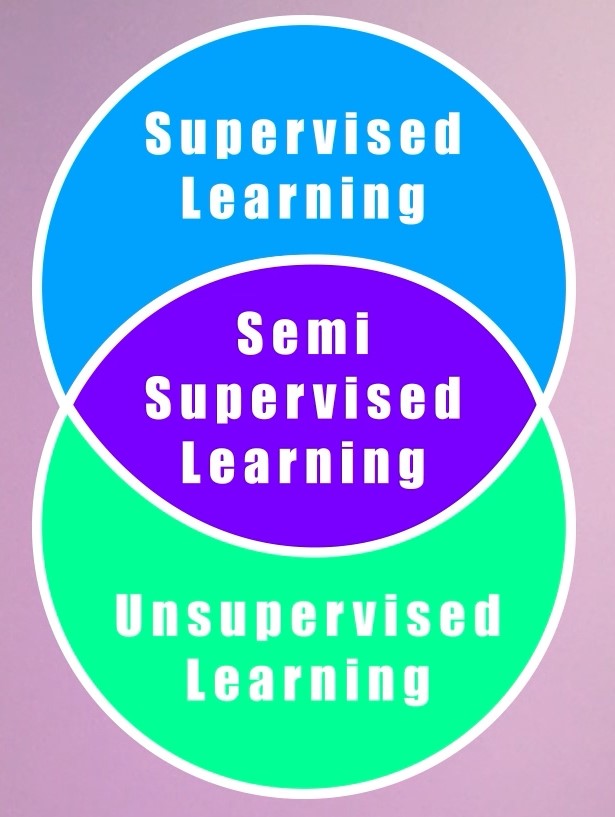
We have already learned about Core ML branches, Supervised Learning, Unsupervised Learning, and Reinforcement Learning, so now it’s time to explore hybrid branches, which use a mix of techniques from these three core branches. The two most useful hybrid fields are; Semi-Supervised Learning and Self-Supervised Learning. And both of these hybrid fields actually fall in a category of Machine Learning called Weak Supervision. Don’t worry I’ll explain all the terms.

The aim of hybrid fields like Semi-Supervised and Self-Supervised learning is to come up with approaches that bypass the time-consuming manual data labeling process involved in Supervised Learning.
So here’s the thing supervised learning is the most popular category of machine learning and it has the most applications in the industry and In today’s era where an everyday people are uploading images, text, blogposts in huge quantities, we’re at a point where we could train supervised models for almost anything with reasonable accuracy but here’s the issue, even though we have lots and lots of data, it’s actually very costly and time-consuming to label all of it.
So what we need to do is somehow use methods that are as effective as supervised learning but don’t require us, humans, to label all the data. This is where these hybrid fields come up, and almost all of these are essentially trying to solve the same problem.
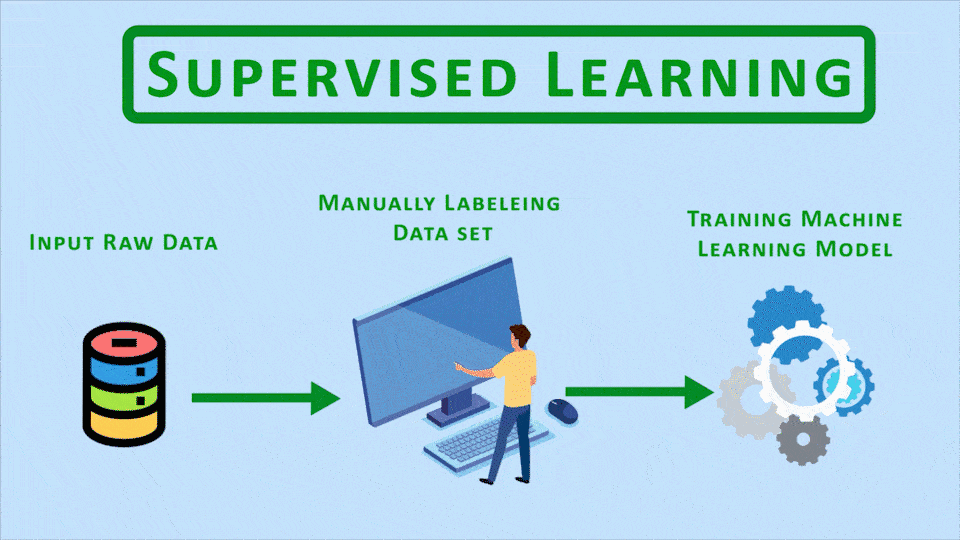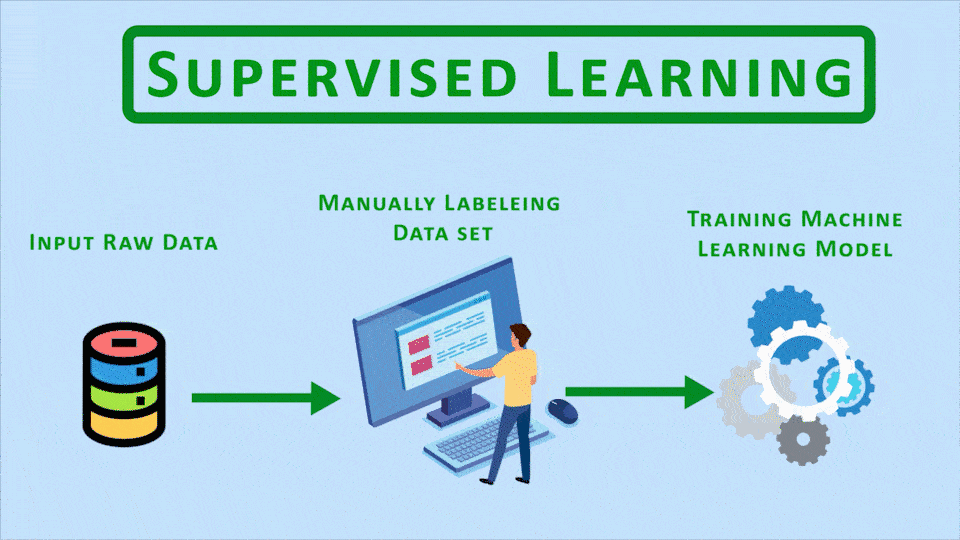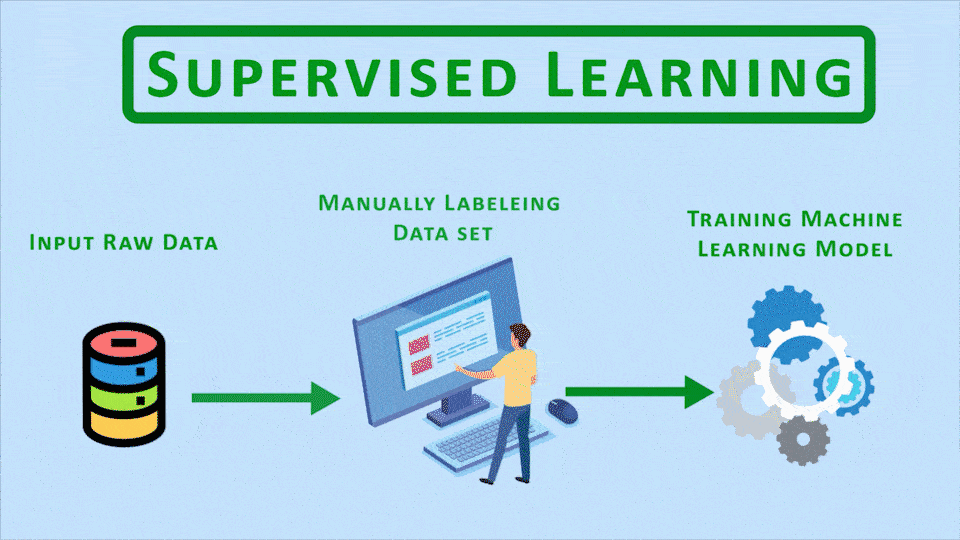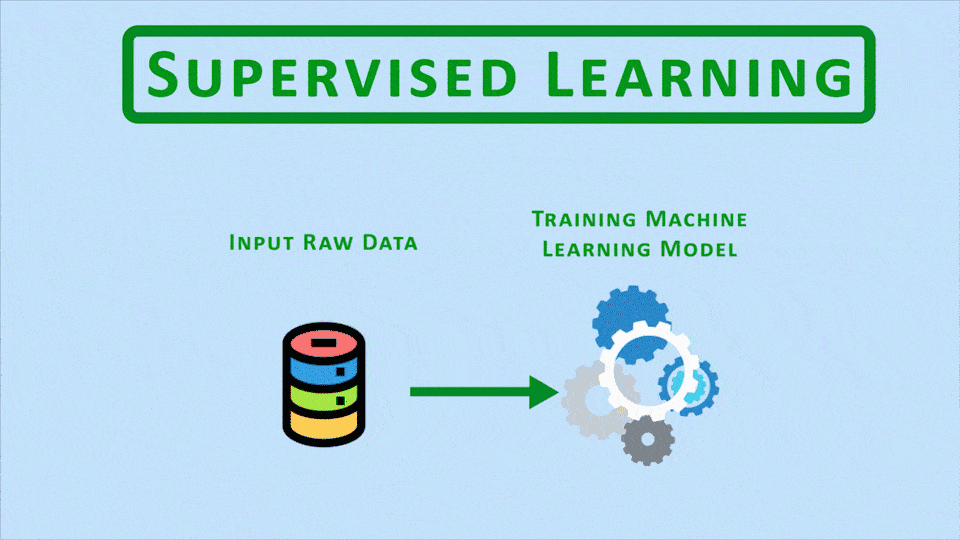
There are some other approaches out there as well, like the Multi-Instance Learning and some others that also, but we won’t be going over those in this tutorial as Semi-Supervised and Self-Supervised Learning are more frequently used than the other approaches.
Semi-Supervised Learning
Now let’s first talk about Semi-Supervised Learning. This type of learning approach lies in between Supervised Learning and Unsupervised Learning as in this approach, some of the data is labeled but most of it is still unlabelled.
Unlike supervised or unsupervised learning, semi-supervised learning is not a full-fledged branch of ML rather it’s just an approach, where you use a combination of supervised and unsupervised learning techniques together.
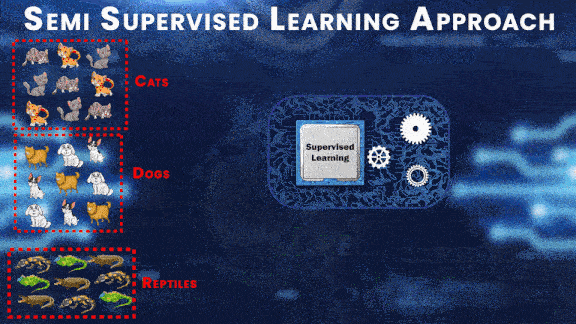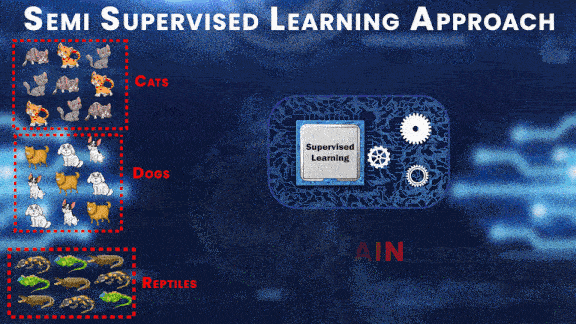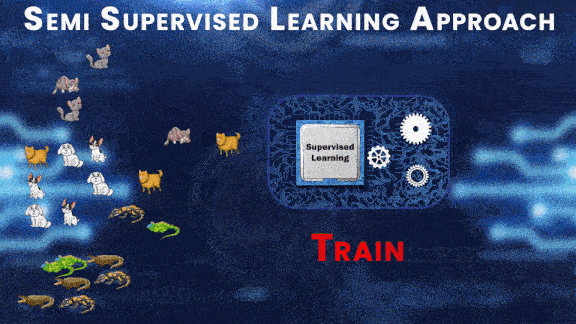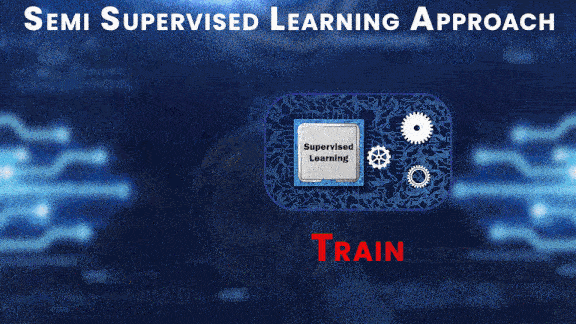
Let’s try to understand this approach with the help of an example; suppose you have a large dataset with 3 classes, cats, dogs, and reptiles. First, you label a portion of this dataset, and train a supervised model on this small labeled dataset.

After training, you can test this model on the labeled dataset and then use the output predictions from this model as labels for the unlabeled examples.

And then after performing prediction on all the unlabeled examples and generating the labels for the whole dataset, you can train the final model on the complete dataset.
Awesome right? With this trick, we’re cutting down the data annotation effort by 10x or more. And we’re still training a good mode.
But there is one thing that I left out, since the initial model was trained on a tiny portion of the original dataset it wouldn’t be that accurate in predicting new samples. So when you’re using the predictions of this model to label the unlabelled portion of the data, an additional step that you can take is to ignore predictions that have low confidence or confidence below a certain threshold.
This way you can perform multiple passes of predicting and training until your model is confident in predicting most of the examples. This additional step will help you avoid lots of mislabeled examples.
Note, what I’ve just explained is just one Semi-Supervised Learning approach and there are other variations of it as well.
It’s called semi-supervised since you’re using both labeled data and unlabeled data and this approach is often used when labeling all of the data is too expensive or time-consuming. For example, If you’re trying to label medical images then it’s really expensive to hire lots of doctors to label thousands of images, so this is where semi-supervised learning would help.
When you search on google for something, google uses a semi-supervised learning approach to determine the relevant web pages to show you based on your query.

Self-Supervised Learning
Alright now let’s talk about the Self-Supervised Learning, a hybrid field that has gotten a lot of recognition in the last few years, as mentioned above, it is also a type of a weak supervision technique and it also lies somewhere in between unsupervised and supervised learning.
Self-supervised learning is inspired by how we humans as babies pick things up and build up complex relations between objects without supervision, for example, a child can understand how far an object is by using the object’s size, or tell if a certain object has left the scene or not and we do all this without any external information or instruction.

Supervised AI algorithms today are nowhere close to this level of generalization and complex relation mapping of objects. But still, maybe we can try to build systems that can first learn patterns in the data like unsupervised learning and then understand relations between different parts of input data and then somehow use that information to label the input data and then train on that labeled data just like supervised learning.

This in summary is Self-Supervised Learning, where the whole intention is to somehow automatically label the training data by finding and exploiting relations or correlations between different parts of the input data, this way we don’t have to rely on human annotations. For example, in this paper, the authors successfully applied Self-Supervised Learning and used the motion segmentation technique to estimate the relative depth of scenes, and no human annotations were needed.
Now let’s try to understand this with the help of an example; Suppose you’re trying to train an object detector to detect zebras. Here are the steps you will follow; First, you will take the unlabeled dataset and create a pretext task so the model can learn relations in the data.
A very basic pretext task could be that you take each image and randomly crop out a segment from the image and then ask the network to fill this gap. The network will try to fill this gap, you will then compare the network’s result with the original cropped segment and determine how wrong the prediction was, and relay the feedback back to the network.

This whole process will repeat over and over again until the network learns to fill the gaps properly, which would mean the network has learned how a zebra looks like. Then in the second step; just like in semi-supervised learning, you will label a very small portion of the dataset with annotations and train the previous zebra model to learn to predict bounding boxes.

Since this model already knows how a zebra looks like, and what body parts it consists of, it can now easily learn to localize it with very few training examples.
This was a very basic example of a self-supervised learning pipeline and the pretext cropping task I mentioned was very basic, in reality, the pretext task for computer vision used in self-supervised learning is more complex.
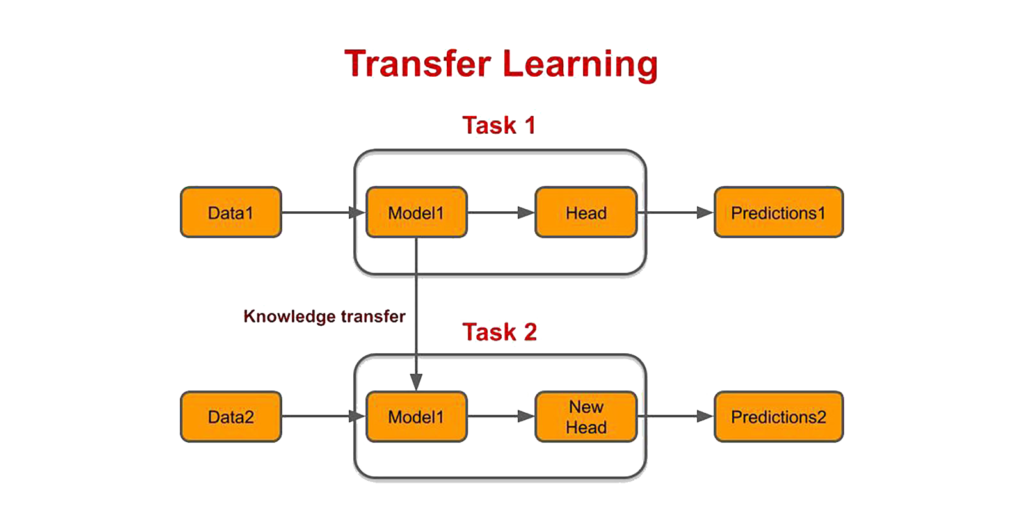
Also If you know about Transfer Learning then you might wonder why not instead of using a pretext task, we instead use transfer learning. Now that could work but there are a lot of times when the problem we’re trying to solve is a lot different than the tasks that existing models were trained on and so in those cases transfer learning doesn’t work as efficiently with limited labeled data.
I should also mention that although self-supervised learning has been successfully used in language-based tasks, it’s still in the adoption and development stage in Computer vision tasks. This is because, unlike text, it’s really hard to predict uncertainty in images, the output is not discrete and there are countless possibilities meaning there is not just one right answer. To learn more about these challenges, watch Yan Lecun’s ICLR presentation on self-supervised learning.
2 years back, Google published the SimCLR network in which they demonstrated an excellent self-supervised learning framework for image data. I would strongly recommend reading this excellent blog post in order to learn more on this topic. There are some very intuitive findings in this article that I can’t cover here.
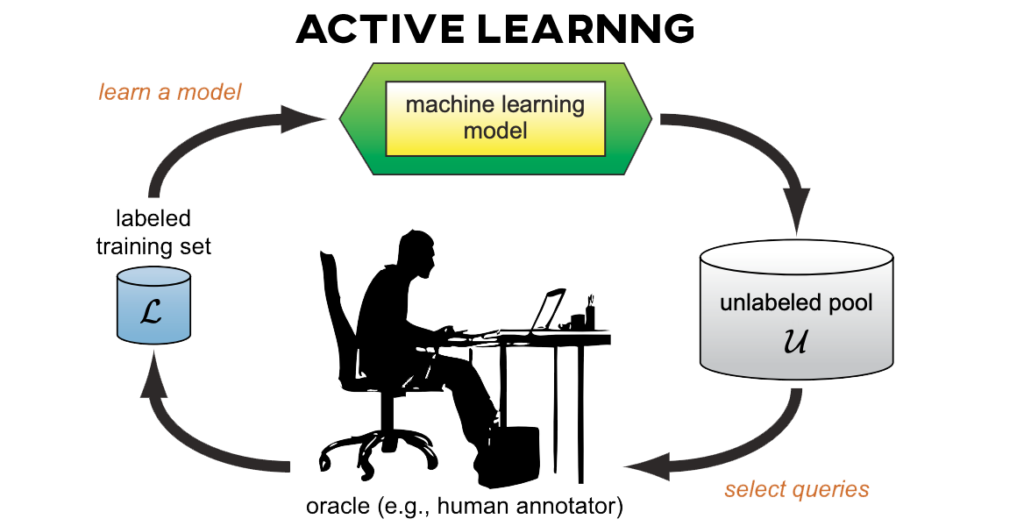
Besides Weak Supervision techniques, there are a few other methods like Transfer Learning and Active Learning. All of the techniques aim to partially or completely automate or reduce the data labeling or annotation process.
And this is a very active area of research these days, weak supervision techniques are closing the performance gap between them and supervised techniques. In the coming years, I expect to see wide adoption of Weak supervision and other similar techniques where manual data labeling is either no longer required or just minimally involved.
In Fact here’s what Yan LeCun, one of the pioneers of modern AI says:
“If artificial intelligence is a cake, self-supervised learning is the bulk of the cake,” “The next revolution in AI will not be supervised, nor purely reinforced”
Alright now let’s talk about Applied Fields of AI, AI industries, applications, and also let’s recap and summarize the entire field of AI and along with some very common issues.
So, here’s the thing … You might have read or heard these phrases.
Branches of AI, sub-branches of AI, Fields of AI, Subfields of AI, Domains of AI, or Subdomains of AI, Applications of AI, Industries of AI, AI paradigms.
Sometimes these phrases are accompanied by words like Applied AI Branches or Major AI Branches etc. And here’s the issue, I’ve seen numerous blog posts and people that used these phrases interchangeably. And I might be slightly guilty of that too. But the thing is, there is no strong consensus on what is major, applied branches, or sub Fields of AI. It’s a huge clutter of terminology out there.
In Fact, I actually googled some of these phrases and clicked to see images. But believe me, it was an abomination, to say the least.
I mean the way people had done categorization of AI Branches was an absolute mess. I mean seriously, the way people had mixed up AI applications with AI industries with AI branches …. it was just chaos… I’m not lying when I say I got a headache watching those graphs.
So here’s what I’m gonna do! I’m going to try to draw an abstract overview of the complete field of AI along with branches, subfields, applications, industries, and other things in this episode.
Complete Overview of AI Field
Now what I’m going to show you is just my personal overview and understanding of the AI field, and it can change as I continue to learn so I don’t expect everyone to agree with this categorization.
One final note, before we start: If you haven’t subscribed then please do so now. I’m planning to release more such tutorials and by subscribing you will get an email every time we release a tutorial.
Alright, now let’s summarize the entire field of Artificial Intelligence. First off, We have Artificial Intelligence, I’m talking about Weak AI Or ANI (Artificial Narrow Intelligence), since we have made no real progress in AGI or ASI, we won’t be talking about that.
Inside AI, there is a subdomain called Machine Learning, now the area besides Machine learning is called Classical AI, this consists of rule-based Symbolic AI, Fuzzy logic, statistical techniques, and other classical methods. The domain of Machine learning itself consists of a set of algorithms that can learn from the data, these are SVM, Random Forest, KNN, etc.
Inside machine learning is a subfield called Deep Learning, which is mostly concerned with Hierarchical learning algorithms called Deep Neural Networks. Now there are many types of Neural nets, e.g. Convolutional networks, LSTM, etc. And each type consists of many architectures which also have many variations.
Now machine learning (Including Deep learning) has 3 core branches or approaches, Supervised Learning, Unsupervised Learning, and Reinforcement Learning, we also have some hybrid branches which combine supervised and unsupervised methods. All of these can be categorized as Weak Supervision methods.
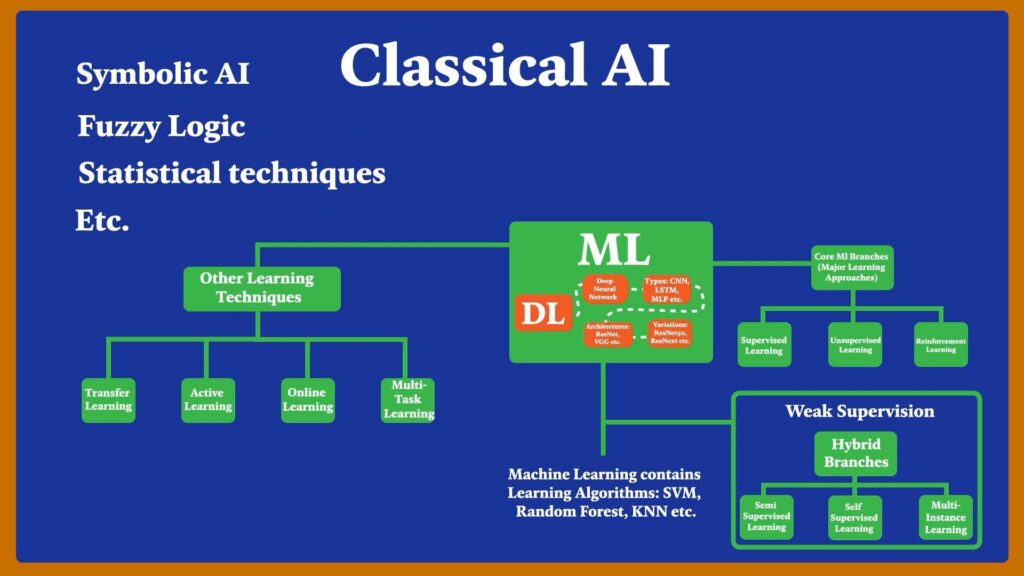
Now when studying machine learning, you might also come across learning approaches like Transfer Learning, Active Learning, and others. These are not broad fields but just learning techniques used in specific circumstances.
Alright now let’s take a look at some applied fields of AI, now there is no strong consensus but according to me there are 4 Applied Fields of AI; Computer Vision, Natural Language Processing, Speech, and Numerical Analysis. All 4 of these Applied fields use algorithms from either Classical AI, Machine Learning, or Deep Learning.
Let’s further look into these fields, Computer Vision can be split into 2 categories, Image Processing where we manipulate, process, or transform images. And Recognition, where we analyze content in images and make sense out of it. A lot of the time when people are talking about computer vision they are only referring to the recognition part.
Natural Language Processing can be broadly split into 2 parts; Natural Language Understanding; where you try to make sense of the textual data, interpret it, and understand its true meaning. And Natural Language Generation; where you try to generate meaningful text.
Btw the task of Language translation like in Google Translate uses both NLU & NLG
Speech can also be divided into 2 categories, Speech Recognition or Speech to text (STT); where you try to build systems that can understand speech and correctly predict the right text for it, and Speech Generation or text-to-speech (TTS); where you try to build systems able to generate realistic human-like speech.
And Finally Numerical Analytics; where you analyze numerical data to either gain meaningful insights or do predictive modeling, meaning you train models to learn from data and make useful predictions based on it.
Now I’m calling this numerical analytics but you can also call this Data Analytics or Data Science. I avoided the word “data” because Image, Text, and Speech are also data types.
And if you think about it, even data types like images, and text are converted to numbers at the end but, right now I’m defining numerical analytics as the field that analyzes numerical data other than these three data types.
Now since I work in Computer Vision, let me expand the computer vision field a bit.
So both of these categories (Image Processing and Recognition) can be further split into two types; Classical vision techniques and Modern vision techniques.
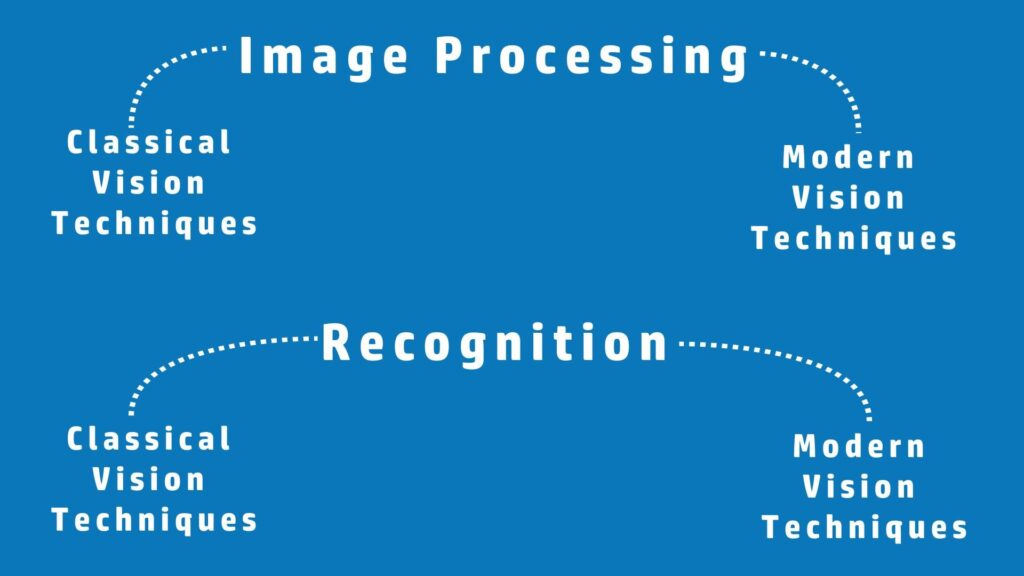
The only difference between the two types is that modern vision techniques use only Deep Learning based methods whereas Classical vision does not. So for example, Classical Image Processing can be things like image resizing, converting an image to grayscale, Canny edge detection, etc.


And Modern Image Processing can be things like Image Colorization via deep learning etc.
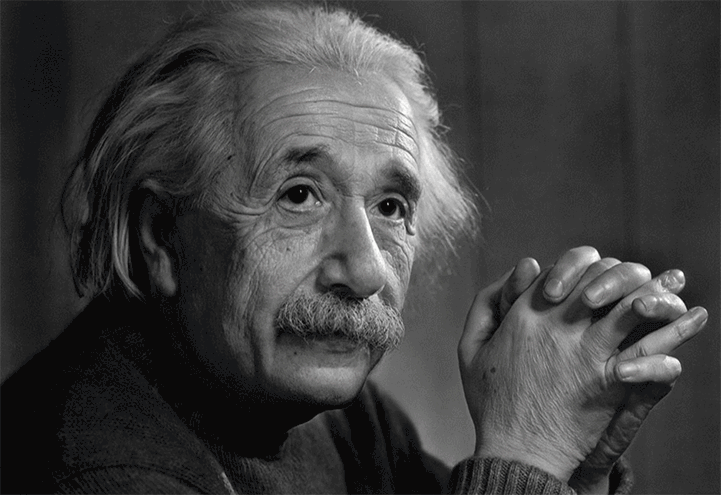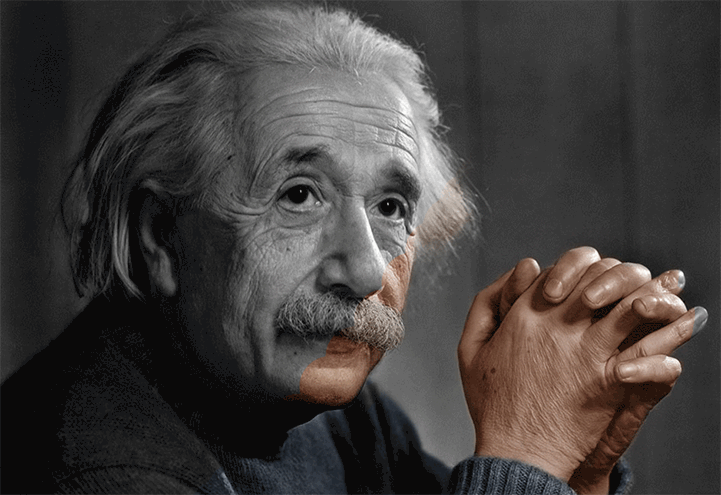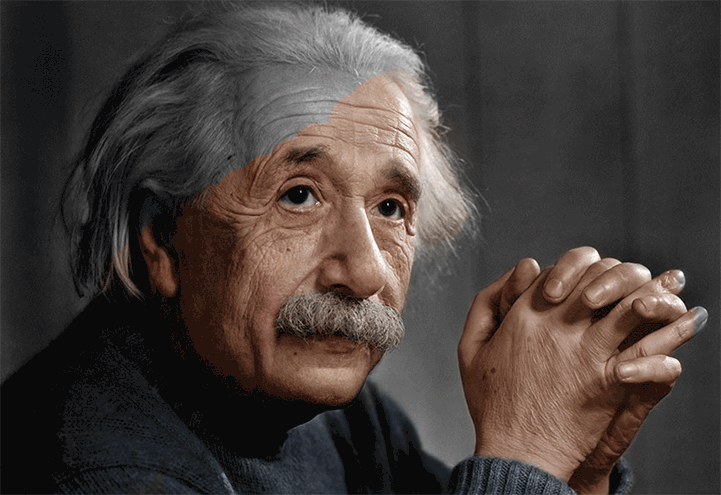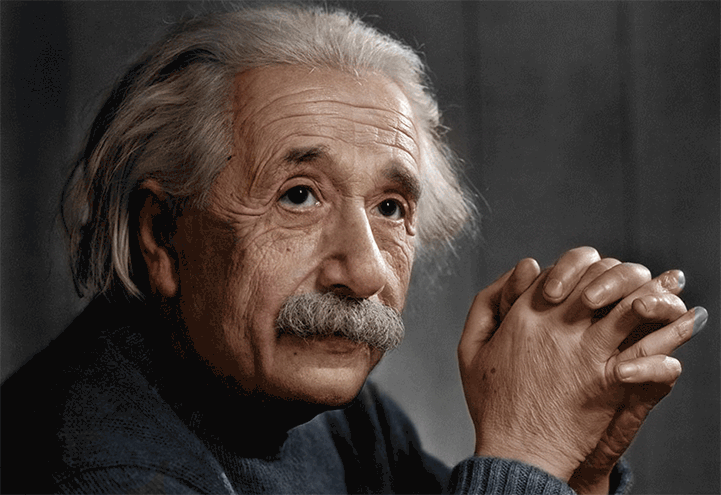
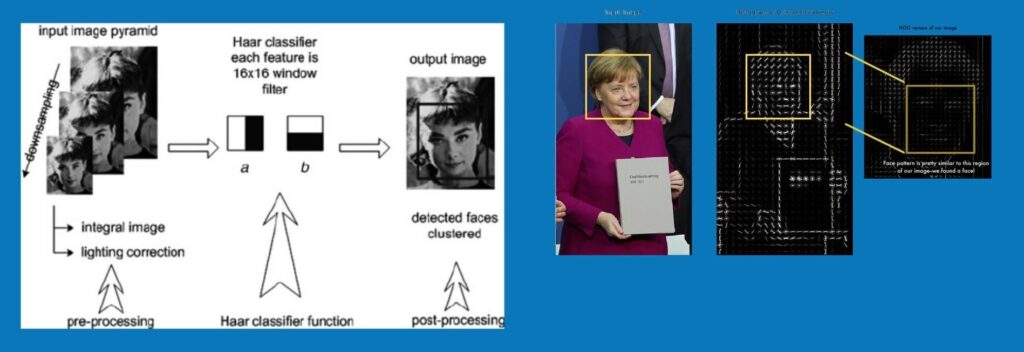
Classical Recognition can be things like: Face Detection with Haar cascades, and Histogram based Object detection.
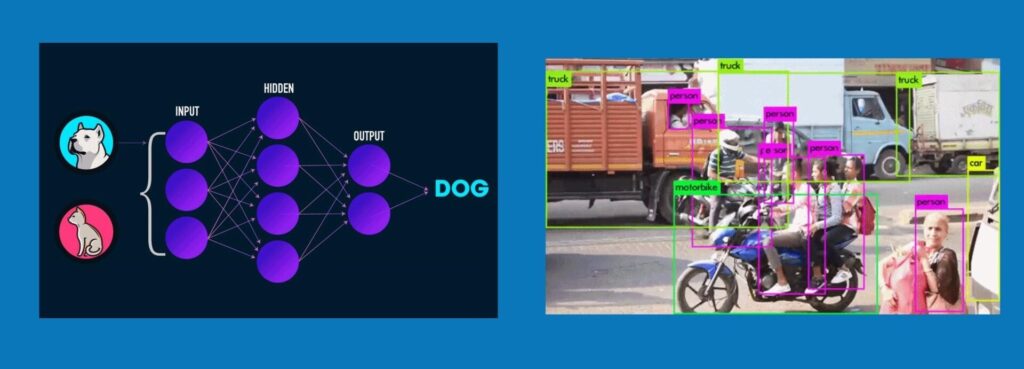
And Modern Recognition can be things like Image Classification, Object Detection using neural networks, etc.
So these were Applied Fields of AI, Alright now let’s take a look at some Applied SubFields of AI. I’m defining Applied subfields as those fields that are built around certain specialized topics of any of the 4 applied fields I’ve mentioned.
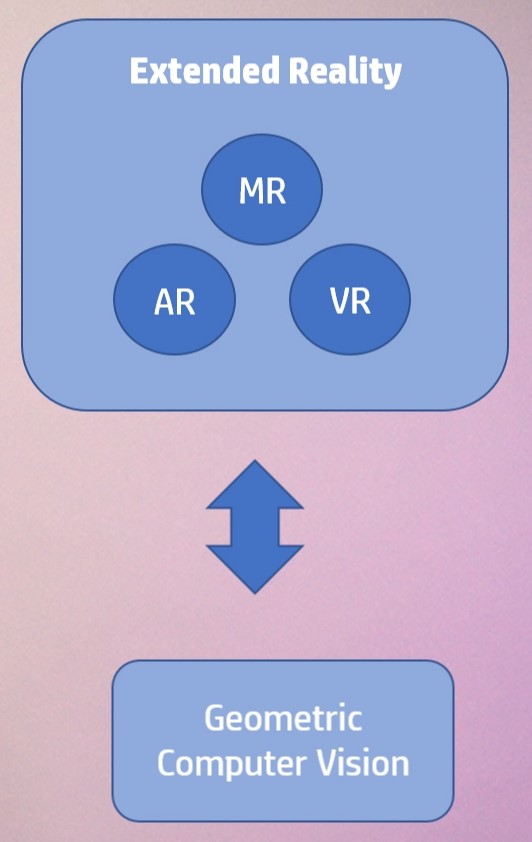
For example, Extended Reality is an applied subfield of AI built around a particular set of computer vision algorithms. It consists of Virtual Reality;

Augmented Reality;

and Mixed Reality;

You can even consider Extended Reality as a subdomain of Computer Vision. It’s worth mentioning that most of the computer vision techniques used in Extended reality itself fall in another domain of Computer Vision called Geometric Computer Vision, these algorithms deal with geometric relations between the 3D world and its projection into a 2D image.
There are many applied AI Subfields, another example of this would be Expert Systems which is an AI system that emulates the decision-making ability of a human expert.
So consider a Medical Diagnostic app that can take pictures of your skin and then a computer vision algorithm evaluates the picture to determine if you have any skin diseases.
Now, this system is performing a task that a dermatologist (skin expert) does, so it’s an example of an Expert system.

Rule-based Expert Systems became really popular in the 1980s and were considered a major feat in AI. These systems had two parts, a knowledge base, (A database containing all the facts provided by a human expert) and an inference engine that used the knowledge base and the observations from the user to give out results.
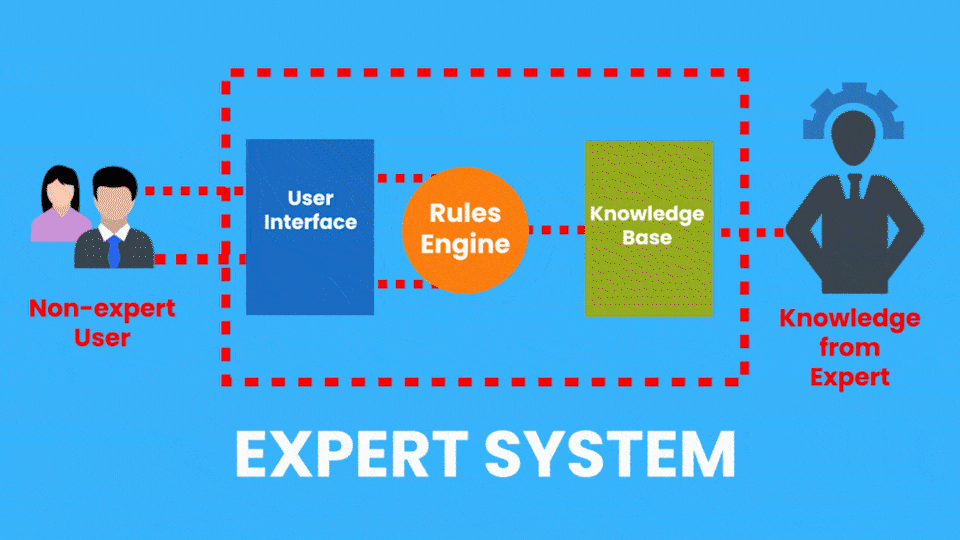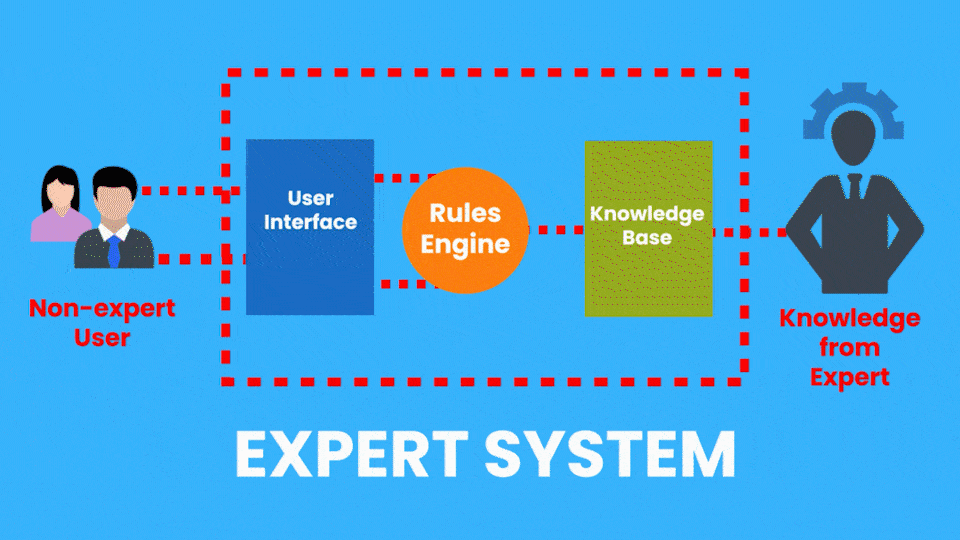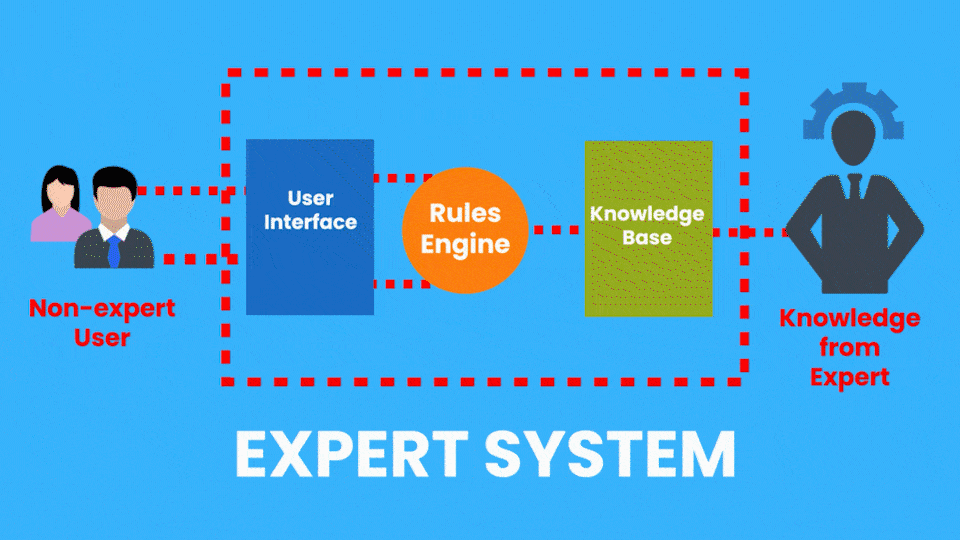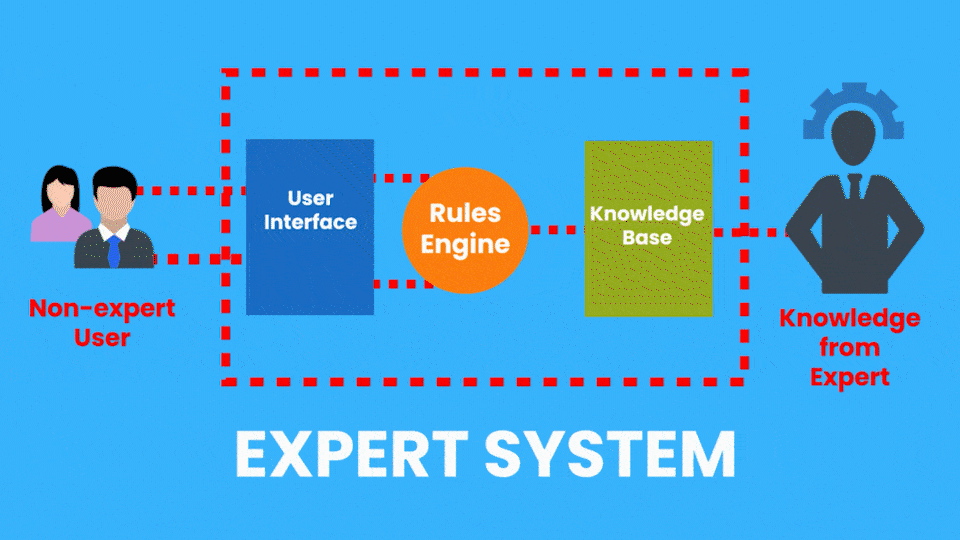
Although these types of expert systems are still used today, they have serious limitations. Now the example of the Expert system I just gave is from the Healthcare Industry and Expert systems can be found in other industries too.
Speaking of industries, let’s talk about AI applications used in industries. So these days AI is used in almost any industry you can think of, some popular categories are Automotive, Finance, Healthcare, Robotics, and others.
Within each Industry, you will find AI applications like self-driving cars, fraud detection, etc. All these applications are using methods & techniques from one of the 4 Applied AI Fields.
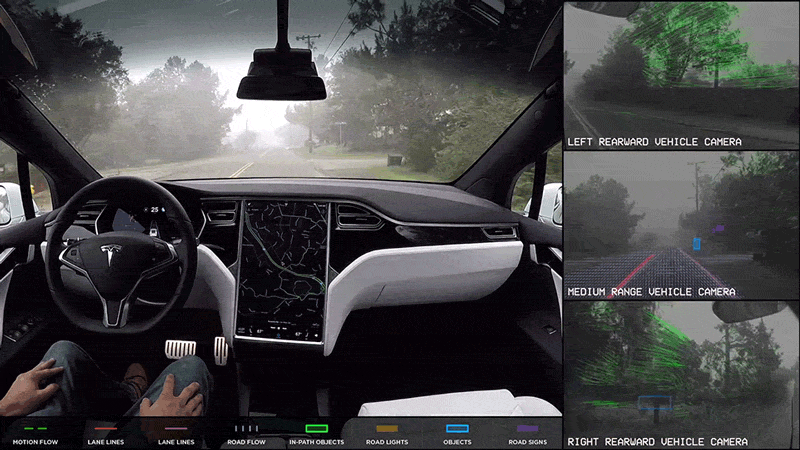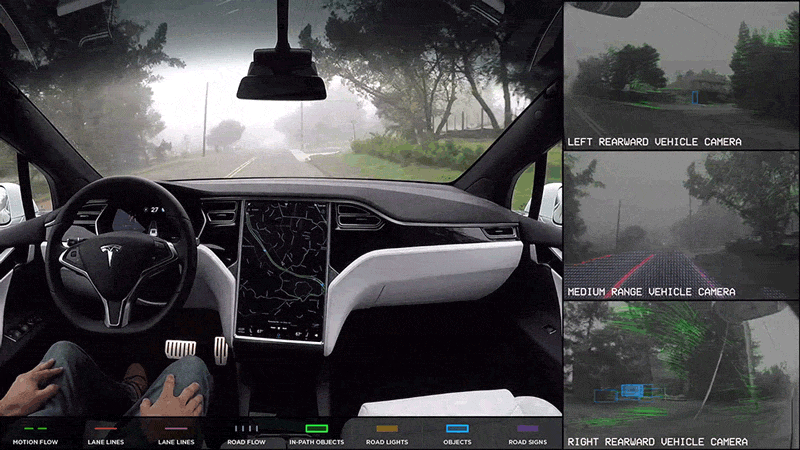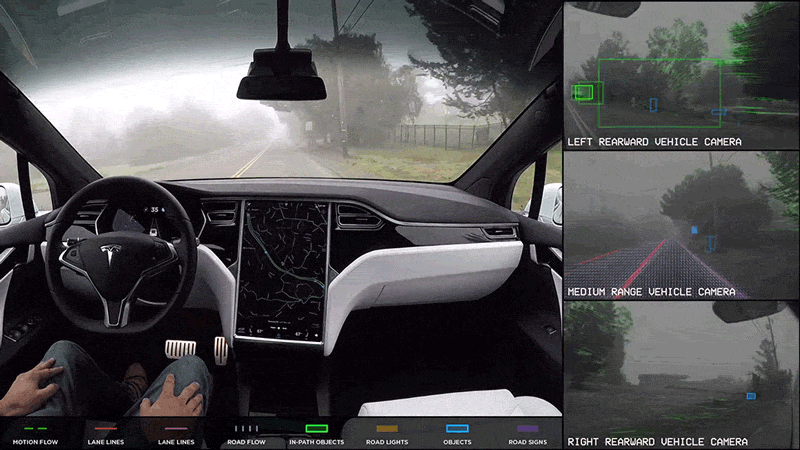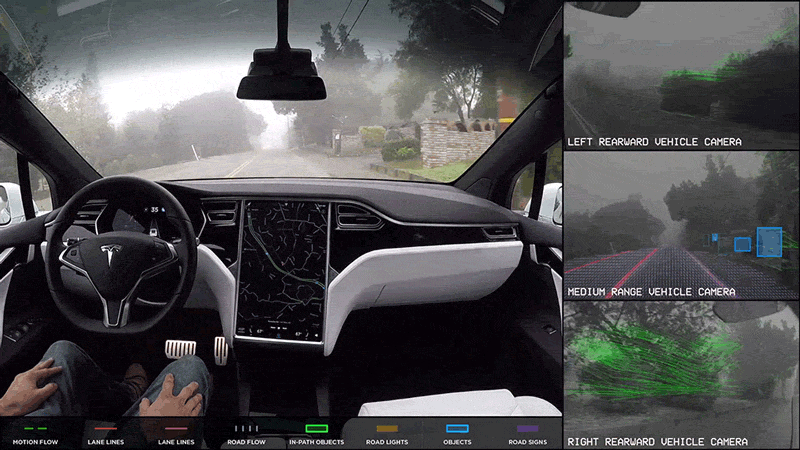
There are many applications that fail in multiple industries, for example, a humanoid robot built for amusement will fall in robotics and the entertainment industry. While the Self Driving car technologies fall into the transportation and automotive industry.
Also, an industry may split into subcategories. For example, Digital Media can be split into social media, streaming media, and other niche industries. By the way, most media sites use Recommendation Systems, which is yet another applied AI subdomain.

Join My Course Computer Vision For Building Cutting Edge Applications Course

The only course out there that goes beyond basic AI Applications and teaches you how to create next-level apps that utilize physics, deep learning, classical image processing, hand and body gestures. Don’t miss your chance to level up and take your career to new heights
You’ll Learn about:
- Creating GUI interfaces for python AI scripts.
- Creating .exe DL applications
- Using a Physics library in Python & integrating it with AI
- Advance Image Processing Skills
- Advance Gesture Recognition with Mediapipe
- Task Automation with AI & CV
- Training an SVM machine Learning Model.
- Creating & Cleaning an ML dataset from scratch.
- Training DL models & how to use CNN’s & LSTMS.
- Creating 10 Advance AI/CV Applications
- & More
Whether you’re a seasoned AI professional or someone just looking to start out in AI, this is the course that will teach you, how to Architect & Build complex, real world and thrilling AI ap
Summary
Alright, so this was a high-level overview of the complete field of AI. Not everyone would agree with this categorization, but this categorization is necessary when you’re deciding which area of AI to focus on and how all the fields are connected to each other, and personally, I think this is one of the simplest and most intuitive abstract overviews of the AI field that you’ll find out there. Obviously, It was not meant to cover everything, but a high-level overview of the field.
This Concludes the 4th and final part of our Artificial Intelligence – 4 levels Explanation series. If you enjoyed this episode of computer vision for everyone then do subscribe to the Bleed AI YouTube channel and share it with your colleagues. Thank you.





Ready to seriously dive into State of the Art AI & Computer Vision?
Then Sign up for these premium Courses by Bleed AI
Also note, I’m pausing the CVFE episodes on youtube for now because of high production costs and will continue with normal videos for now.
[optin-monster-inline slug=”s1o74crxccvkldf3pw2z”]






0 Comments